Reference
https://iai.postech.ac.kr/teaching/machine-learning
https://iai.postech.ac.kr/teaching/deep-learning
위 링크의 강의 내용에 기반하여 중요하거나 이해가 어려웠던 부분들을 정리하여 작성하였고,
모든 강의 슬라이드의 인용은 저작권자의 허가를 받았습니다.
또한, 모든 내용은 아래 Notion에서 더 편하게 확인하실 수 있습니다.
>>노션 링크<<
Keywords
- covariance, correlation coefficient
- Dimension Reduction
- PCA algorithm
- covariance matrix, eigenvalue, eigenvector
Multivariate Statistics


Sample Variance: 단일 변수에 대한 분산(variance)
Sample Covariance: (*여기서는 2차원) 두 개의 변수에 대한 공분산.
⇒ 사실 $S_x$ 도 covariance의 시점에서, $S_{xx}$로 바라볼 수 있는 것.
그렇게 되면, $S_{xx} = \frac{1}{m-1}\sum{(x^i-\bar{x})(x^i-\bar{x})}$ 임. (Sample Variance의 식과 동일)
Sample Covariance Matrix: (위의 Sample Covariance를 참고하여-)
$S = \left[
\begin{matrix}
S_{xx} & S_{xy} \
S_{yx} & S_{yy} \
\end{matrix}
\right]$ 와 같음.
Sample Corellation coefficient: 상관계수. 공분산을 각 변수의 표준편차의 곱으로 나눈 것.
Covariance를 normalizing하는 느낌으로 받아들이면 될 듯.
*두 변수 사이의 Strength of linear relationship 이다.
(변수 간의 선형 관계의 강도와 방향을 의미, -1 ~ 1 사이의 값을 가지며, 1에 가까울 수록 양의 상관관계, -1에 가까울수록 음의 상관관계, 0에 가까울수록 선형 상관관계가 존재하지 않음을 의미.)
Dimension Reduction


Dimension Reduction
- 고차원의 data를 저차원으로 표현
- information의 손실을 최소화하며, useful한 representation을 얻을 수 있도록
이의 장점?
- 저차원에서 바라봄으로써, 시각적으로 data의 구조, 특성을 파악 가능
- overfitting의 가능성을 낮춤. (dimension 낮춤)
- training 속도 상승 / 저장공간 적게 사용
- Dim. Reduction ≠ feature selection
- Dim. Reduction ⇒ 모든 feature를 버리지 않고 새로운 dimension으로 표현.
- feature selection ⇒ 큰 영향이 없는 feature를 drop
- $\therefore$ Dim. Reduction → feature drop이 아닌, extract의 관점.
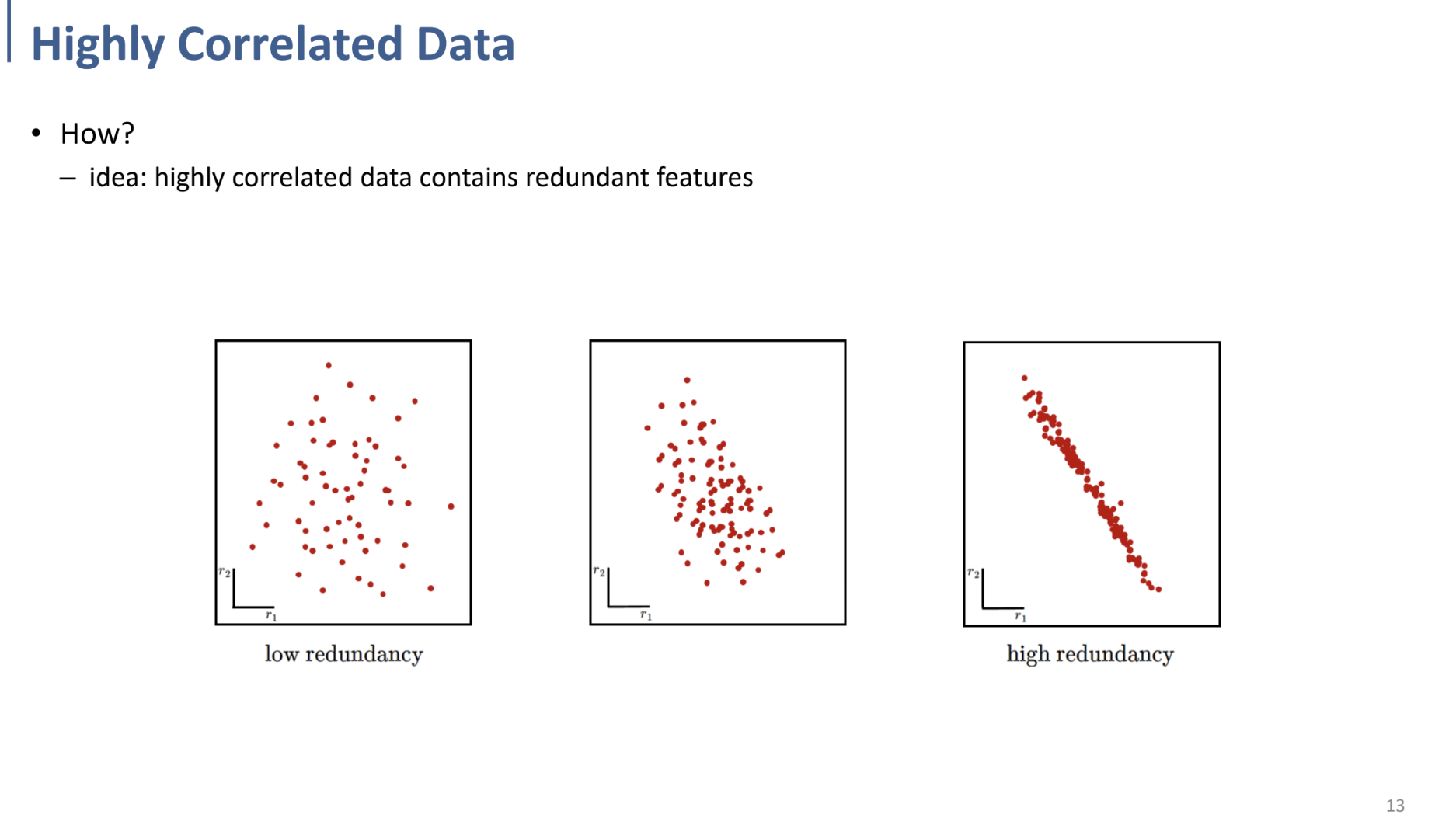
high redundancy → Dim. Reduction의 가능성이 큼.
($x_1$을 알면 어느정도 correlation이 있기 때문에 (선형적인 연관이 존재) $x_2$를 predict 가능한.)
PCA: Introduction
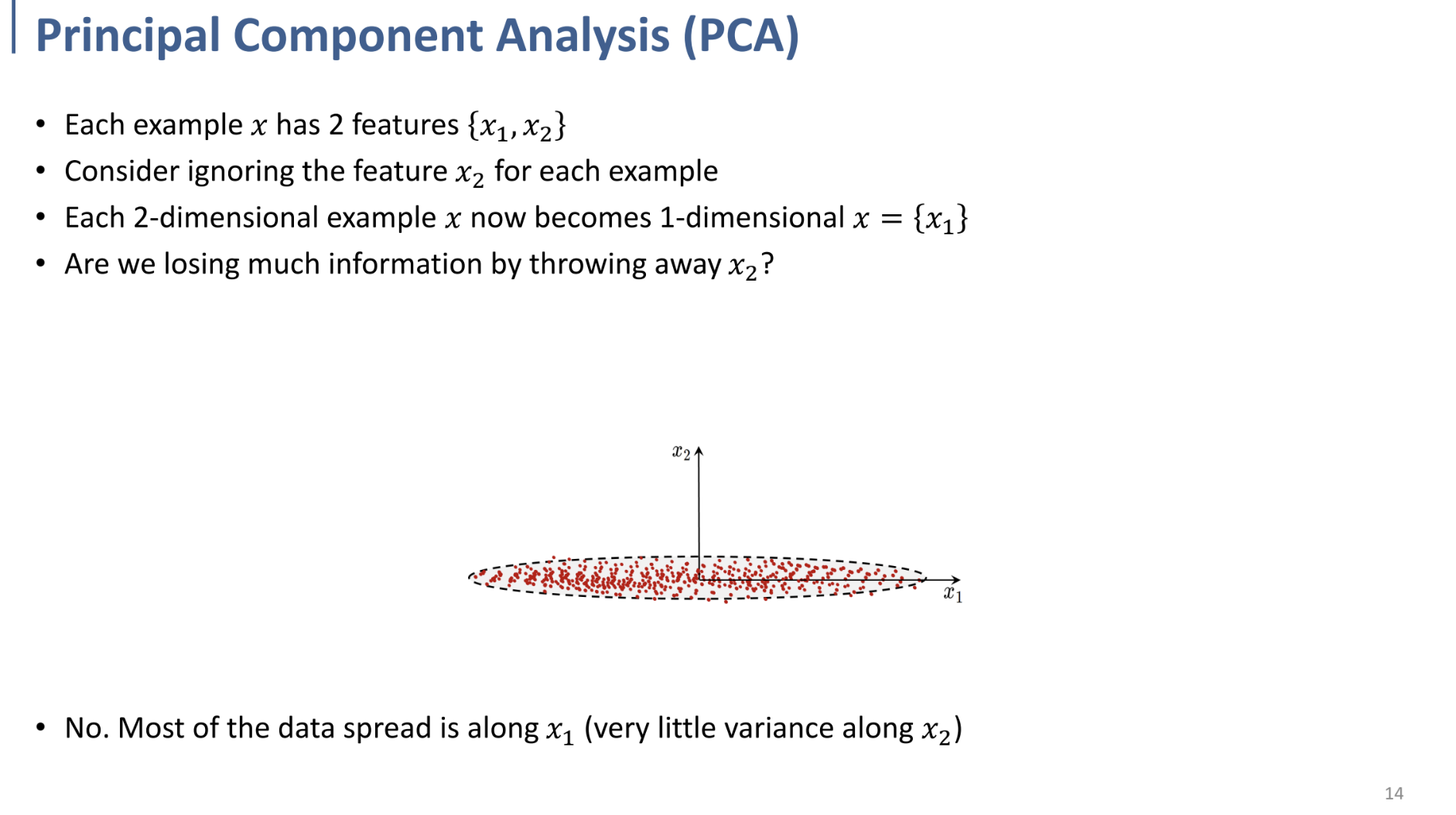
왼쪽과 같은 2D dataset에서 $x_2$축에 대한 정보를 무시하고, $x_1$만 남긴다고 해도($x_1$축으로 projection), 정보의 손실이 크지 않음.
대부분의 data가 $x_1$ 축에 대해 분포되어 있음.
→ 이러한 아이디어를 이용한다!
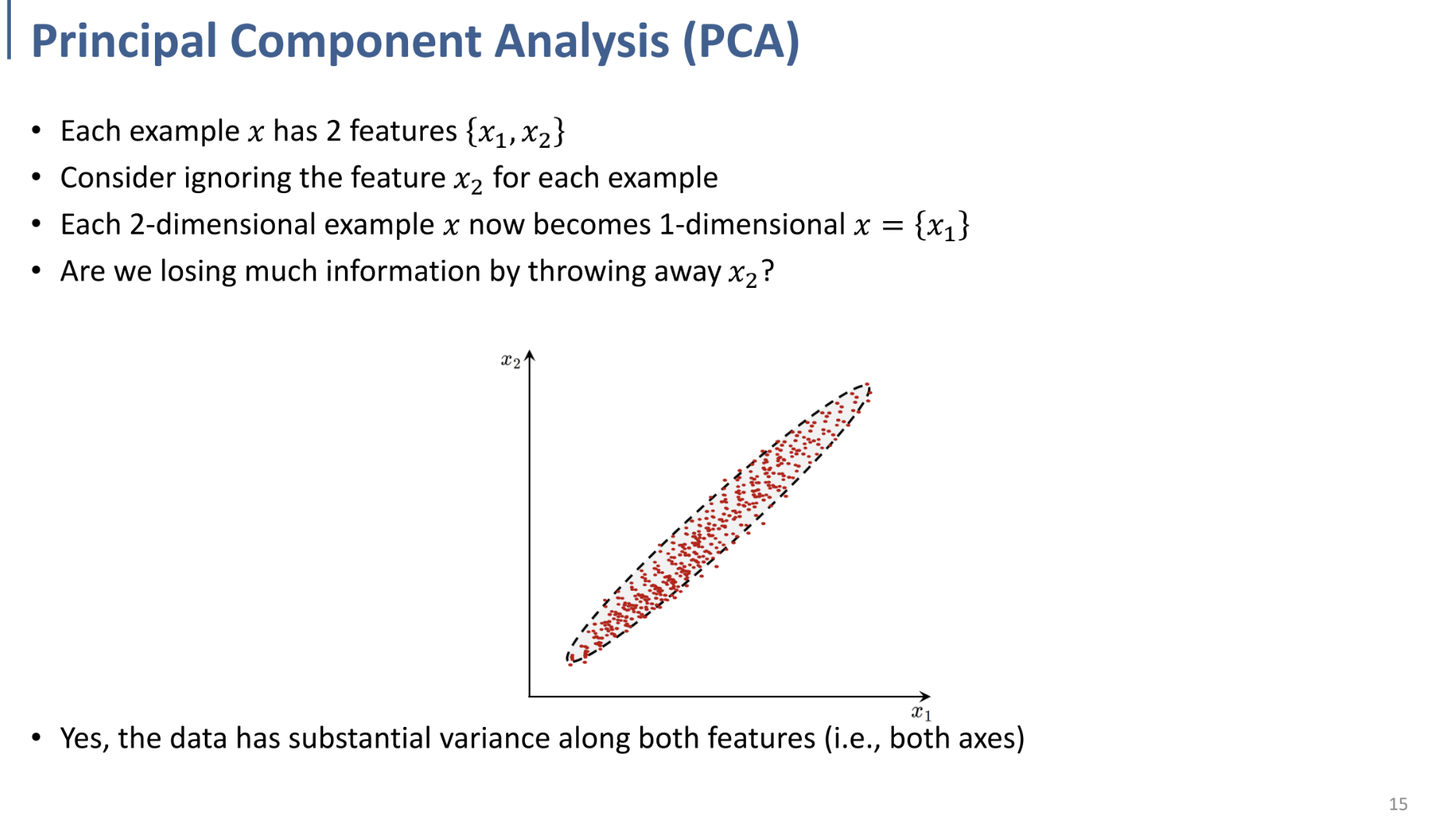
오른쪽과 같은 2D dataset에서는 $x_2$축에 대한 정보를 무시하면 정보의 손실이 큼.
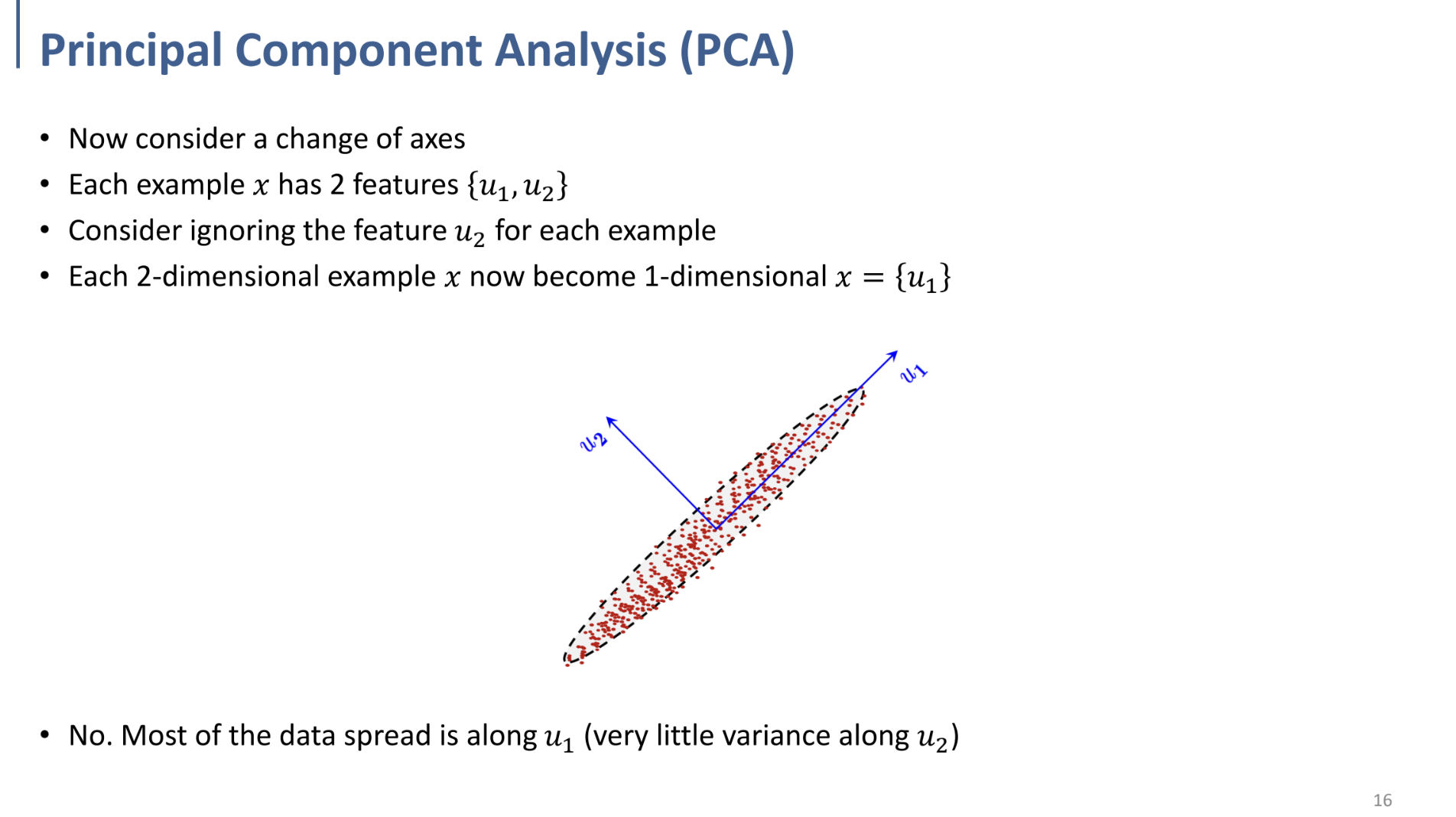
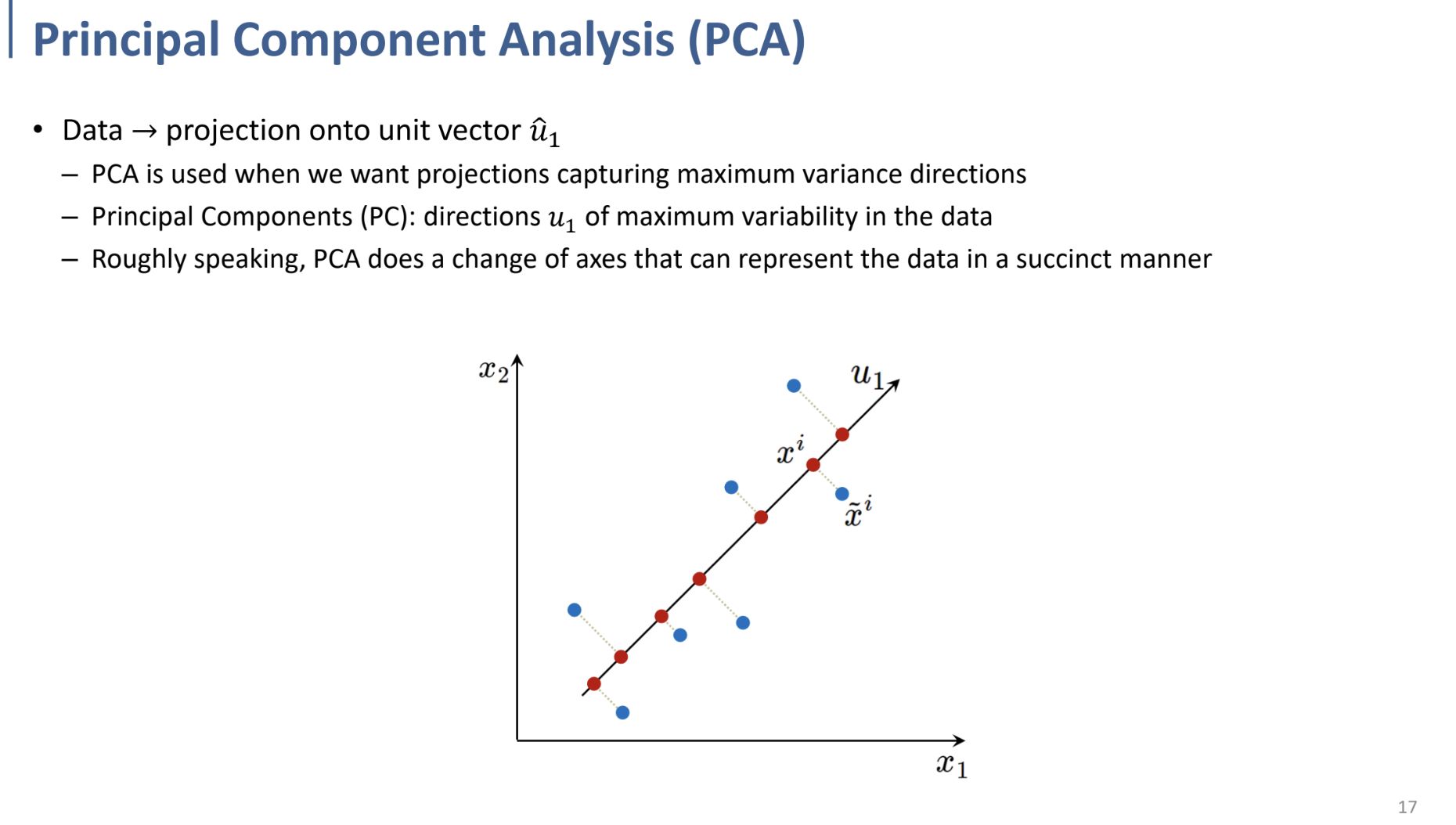
따라서, 이와 같이 새로운 두 축 $u_1, u_2$로 바라본다는 아이디어.
가장 variance가 높은 축을 기준으로 orthogonal한 $u_2$축 같이 정의.
→ $u_2$를 제거하여 dim. Reduction.
PCA에서 PC(Principal Component, 주성분): data에서 max variability를 갖는 방향 ($u_1$)
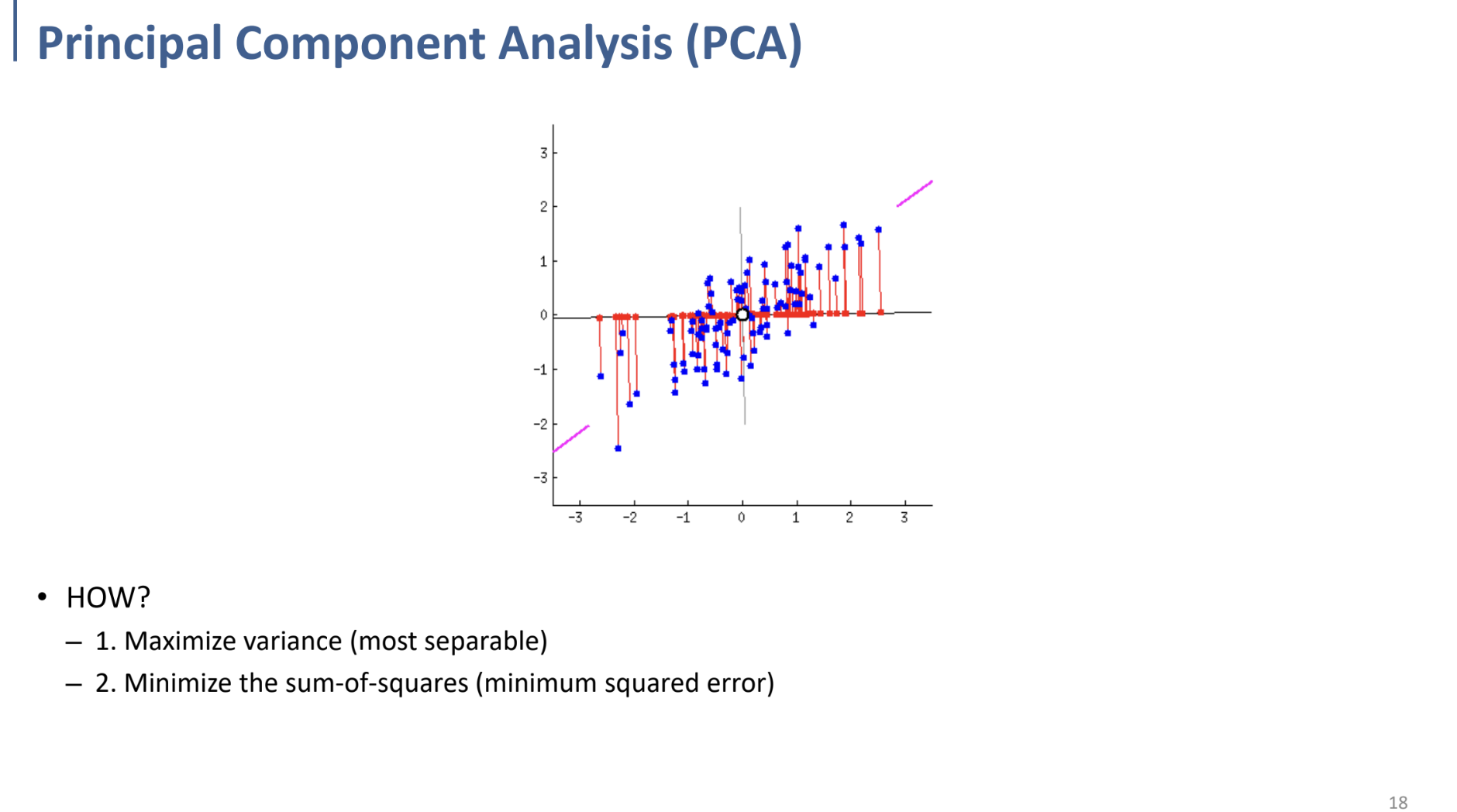
또는, Sum of Square (lost information)을 minimize하는 방식으로 Reduction.
PCA: algorithm

PCA를 수행하기 이전 Preprocessing 과정
- Shift to zero mean: 모든 data에서 평균을 빼서, 평균이 0이 되도록 변경.
- Rescaling (unit variance): 분산을 구해 표준편차로 모든 data를 나누어 rescaling.
→ 이렇게 하면 분산이 1이 됨. (unit variance)

전처리 이후, Variance를 maximize하는 과정.
projection을 수행했을 때 variance를 maximize할 수 있는 unit vector $u$를 찾기.
(첫번째 줄)
u 방향으로 x를 projection한 결과는
$x\cdot u = |x||u|cos\theta = |x|cos\theta$ 임. ($|u|=1.$ unit vector이므로)
$u \cdot x$를 대수적으로 표현하면, $u^T x = x^Tu$ 이므로, 모두 동치.
(여기서 $u^T x = x^Tu$가 성립하는 것은 각각 1 x n과 n x 1 벡터이기 때문에, 내적이고, 결과가 스칼라값이기 때문. 일반적으로는 특별한 경우 외에 성립하지 않음.)
(두번째 줄)
$X^2 = X^TX$, $(x^Tu)^T = u^Tx$ 임을 이용.
(세번째 줄)