![[논문 리뷰] CLIP (Learning Transferable Visual Models From Natural Language Supervision)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fvyurh%2FbtsJ6WdU2yD%2FcnKXrgSjWpFM3hGMkdKSv0%2Fimg.png)
[딥러닝 논문 리뷰 시리즈]
노션에서 작성한 글을 옮겼으며, 아래 노션에서 더 깔끔하게 읽으실 수 있습니다.
CLIP (Learning Transferable Visual Models From Natural Language Supervision) | Notion
Introduction & Motivation
skillful-freighter-f4a.notion.site
Introduction & Motivation
- NLP 분야에서는 Transformer의 발표 이후, Seq2Seq와는 다르게 긴 문장도 잘 처리할 수 있는 능력을 갖게 되었다.
- 그러한 능력을 기반으로, 인터넷 상의 많은 raw text data를 이용하여 큰 모델, 큰 데이터셋을 이용하여 대규모로 학습(Pre-train)할 수 있게 되었음. → 이러한 배경에 힘입어, NLP 쪽은 혁명적으로 발전하여 GPT, BERT와 같은 LLM 등이 등장하게 되었다.
- 그러나 Vision 분야에서는 아직 ImageNet과 같은 제한된 크기의 Labeled dataset이 관행적으로 사용되고 있었음. ImageNet의 데이터셋의 양이 적은 편은 아니나, 사람이 직접 사전 처리를 해주어야 하는 labeled dataset으로 학습하는 방식은 사용할 수 있는 데이터의 개수에 한계가 있었다.
- NLP에서와 같이, Vision 분야에서도 대규모의 raw data(Image-text data)를 이용하여 학습(Pre-train)하는 방식을 차용한다면, 어떤 돌파구가 될 수 있지 않을까 - 라는 생각에서 기존의 한계를 극복하고자 했다.
Approach
1. Natural Language Supervision
- Text data와는 다르게, vision data(image)는 기존의 방법으로는 대규모의 raw data를 이용하여 학습할 수 없었다.
- text는 간단하게 인터넷 상에서 많은 raw한 text data를 가져와 그대로 dataset으로 사용할 수 있었지만, 같은 방법으로 raw image data를 모으기에는, 많은 양의 image에 하나하나 label을 달아줄 수 없었기 때문이다.
- CLIP에서는 대규모의 data를 확보하기 위해, 이러한 문제들을 Natural Language Supervision(자연어 감독)을 사용하였다.
- 이미지에 각각 대응되는 label을 사용하는 것이 아닌, 인터넷 상에서 이미지에 달려 있는 설명 그대로를 대응시켜 이용하자는 것.
- Image(visual) representation을 학습하는 데에 Natural Language Supervision(자연어 감독)을 사용하려는 시도 자체가 이전에 없었던 것은 아니다. 그러나 다른 방법에 비해 성능이 낮았기 때문에, 일반적으로 널리 사용되지 않았다.
- Natural Language Supervision을 이용하는 것이 아니더라도, Image-text 쌍을 학습하는 예시는 이전에도 많이 존재했다. 예를 들어, VirTex, ConVIRT와 같은 것들이 존재한다.
- 각각 간단하게 소개하자면, VirTex에서는 Image-caption 쌍을 이용해 학습하였으며, 이미지로부터 특정 캡션을 생성하는 것을 목표로 학습한다.
학습 과정에서 Image Encoder와 Text Decoder를 동시에 학습하며, 이 task를 통해 간접적으로 Image에 대한 Representation 과정을 학습할 수 있다. - ConVIRT는 CLIP과 꽤나 유사한데, Image-Text 쌍을 Contrastive Learning을 이용해 학습한다.
Image, Text를 각각 encoding하여, 같은 쌍의 image-text 쌍의 임베딩은 가깝게, 다른 쌍은 멀어지도록 학습한다.
학습 과정에서 Image encoder, text encoder가 함께 학습되며, 이미지-텍스트 쌍의 연관성을 학습할 수 있다.
그러나 의료 도메인에 특화된 모델로써, text encoder로 BioBERT를 이용하였고, 의료 도메인 쪽의 데이터만을 활용하였다는 특징이 존재. - 결국 다른 모델들과의 가장 큰 차이점은, 인터넷 상에서 수집한 약 4억 개의 이미지-텍스트 쌍이라는 대규모 데이터를 통해 학습시켜 generality를 얻었다는 것이다.
2. Contrastive Learning, Select Training Method

- VirTex와 같이, 위의 bag-of-word나 transformer를 이용하는 방식은 각 Image에 대해 정확히 대응되는 text를 predict하도록 학습한다. 이러한 접근 방식은 대규모의 데이터를 학습하기에는 시간이 너무 오래 걸린다.
- (위의 이미지에서, 이미 transformer language model이 bag-of-word보다 ImageNet data에 대해 동일한 zero-shot accuracy에 도달하는 데에 3배나 오랜 시간이 걸린다는 것을 알 수 있다. 심지어 transformer 학습에 2배 정도의 compute power를 사용했음에도.)
- 최근 연구에서는(이 논문 기준. 2021.01), 이러한 predict 방식보다 constrastive한 representation learning 방식이 더 나은 representation을 학습할 수 있다는 것을 확인했다.
또한, 위의 그래프와 같이 contrastive objective를 이용함으로써 더 적은 연산을 필요로 한다는 것을 실험적으로 확인하였다.

- CLIP에서는 N개의 Image, text 쌍을 가진 하나의 batch에서, 위 그림과 같이 NxN개의 페어링을 생성한다.
이러한 페어링에서, 원래의 Image-text 쌍에 대한 N개의 페어링의 cosine similarity가 높아지도록, 다른 맞지 않는 N^2-N개의 페어링에 대해서는 cosine similarity가 낮아지도록 학습한다.

- 이러한 cosine similarity에 대해, 위와 같이 symmetric cross entropy loss를 optimize하는 방향으로 학습한다.
- dataset의 크기가 충분히 커서, overfitting에 대해서는 크게 고려하지 않아도 된다.
- 학습 과정에서, Image encoder나 text encoder에 미리 학습된 weight을 이용하여 초기화하지 않고, 처음부터 학습하였다.
- 또한 encoding 결과로부터 multimodal embedding space로의 projection에서, nonlinear projection이 아닌, linear projection만을 사용하였다.
두 방법 사이의 training efficiency를 발견하지 못하여, linear projection을 사용하였다. - (CLIP에서는, image-text 간의 유사도를 softmax를 이용하여 확률값으로 나타냄.)
softmax에서의 logit range를 결정하는 temperature $\tau$는 hyper-parameter화 되지 않기 위해, log-parameterized multiplicative scalar를 통해 training 중 함께 optimize하였다.
3. Select Encoder Model
- CLIP에서는 Image Encoder, Text Encoder를 각각 Constrastive Learning를 통해 학습하게 된다.
- Image encoder는 ResNet 또는 ViT(Vision Transformer)를 이용한다.
- 여기에서 ResNet은, 원본의 버전이 아닌, Global Pooling Layer를 Attention Pooling으로 교체하여 사용한다.
- Attention Pooling은 transformer-style의 멀티헤드 QKV attention - single layer로 구현하고, 그 중 Query 부분은 Image의 global average pooled representation (첫 토큰) 을 사용, 나머지 Key, Value는 GAP를 포함한 모든토큰을 사용한다.
- ViT는 원본 거의 그대로를 사용한다. initializing 과정을 살짝 변형하고, positional embedding 단계에서 추가적인 layer normalize를 거치는 정도가 추가되었다.
- 여기에서 ResNet은, 원본의 버전이 아닌, Global Pooling Layer를 Attention Pooling으로 교체하여 사용한다.
- Text encoder는 Transformer를 사용한다.
- 63M-parameter, 12-layer, 512-wide model with 8 attention head (Radford et al. (2019))
- 최대 sequence 길이는 76.
- Transformer에서의 마지막 토큰인, [EOS]에 해당하는 토큰에 해당하는 vector를 embedding space로 linear projection하여 constrastive learning을 수행하게 된다.
Experiment
1. Zero-shot Transfer
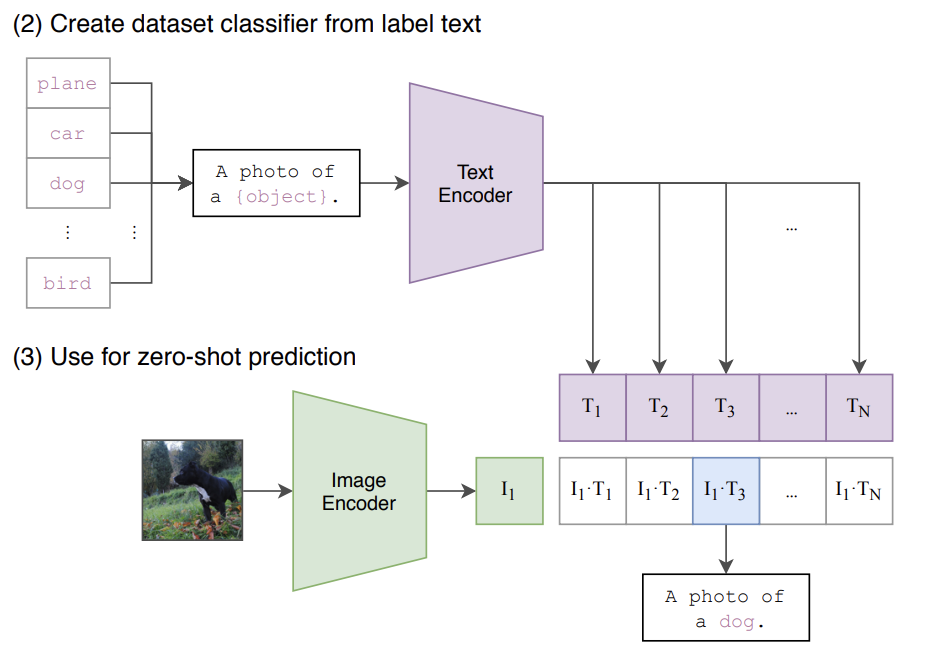
- Image-Natural Language text 쌍에 대해 Pre-train된 CLIP을 이용하여, Zero-shot prediction (Classification)을 수행하도록 할 수 있다.
- dataset에서, dataset에 있는 모든 class(label)의 name을 text snippet으로 변경하고, input image와 함께 encoding하여 cosine similarity를 계산하여 가장 높은 similarity를 가진 text snippet을 선택하면 된다는 것. (그 class로 classify가 되었다고 할 수 있겠다.)
- 논문에서의 과정을 자세히 설명하자면, 위와 같이 생성된 text set과 image를 각각 encoding, 이후 linear projection을 수행하여 embedding dimension에 맞추어 cosine similarity를 계산한다.
이후 이 cosine similarity는 temperature $\tau$ 에 의해 softmax를 거쳐 normalize된다.
- 논문에서의 과정을 자세히 설명하자면, 위와 같이 생성된 text set과 image를 각각 encoding, 이후 linear projection을 수행하여 embedding dimension에 맞추어 cosine similarity를 계산한다.
- 이러한 관점에서 (zero-shot image classification) 바라볼 때, CLIP의 pre-train 과정은 각 배치마다 랜덤하게 생성되는 32768 class, 그리고 각 class마다 1개의 example이 존재하는 dataset에 대해 학습하는 것과 같다고 바라볼 수 있게 된다.
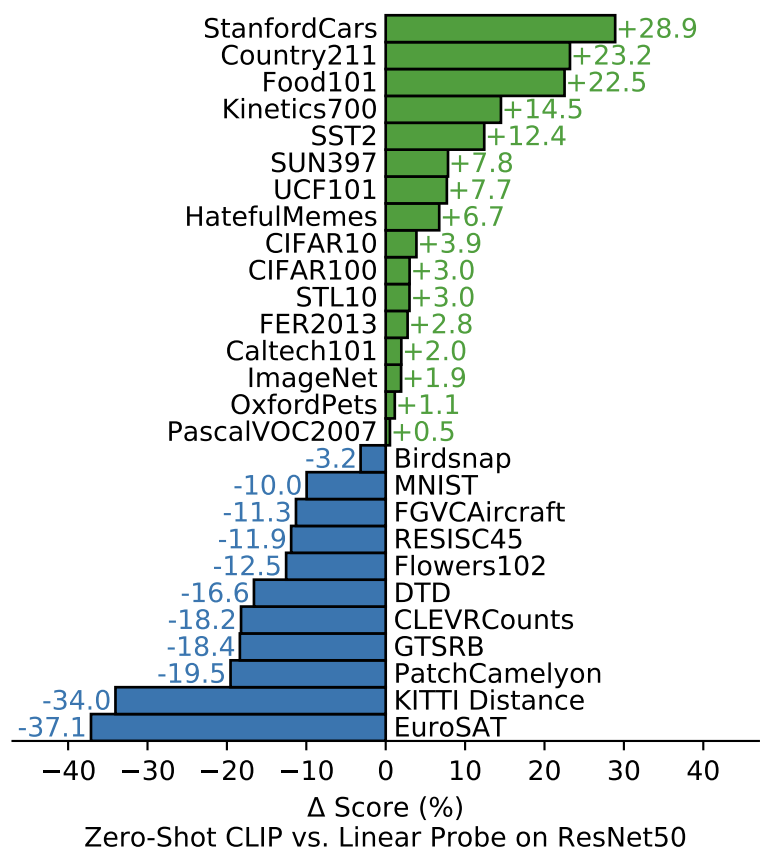
- 이러한 CLIP에서의 Zero-shot 성능이, ResNet에서의 Linear Probing보다 여러 dataset에 대해 (위의 결과에서는 절반 이상의) 성능이 좋다는 결과가 도출되었다.
- 데이터셋의 특성에 따라 추측해 보자면, 비디오의 동작 인식 관련 데이터셋인 Kinetics700, UCF101에서 뛰어난 성능을 보였는데, 이는 Natural Language Supervision을 통해 학습한 결과로써, 동사와 관련된 시각적 개념에 대해 명사 중심의 supervision(ImageNet)보다 더 잘 학습하였다고 추측하였다.
- 또한, 여러 특수하고 복잡한, 그리고 추상적인 dataset에 대해 저조한 성능을 보였다. (ex. 자율 주행-KITTI Distance, 림프절 종양 감지-PatchCamelyon 등)
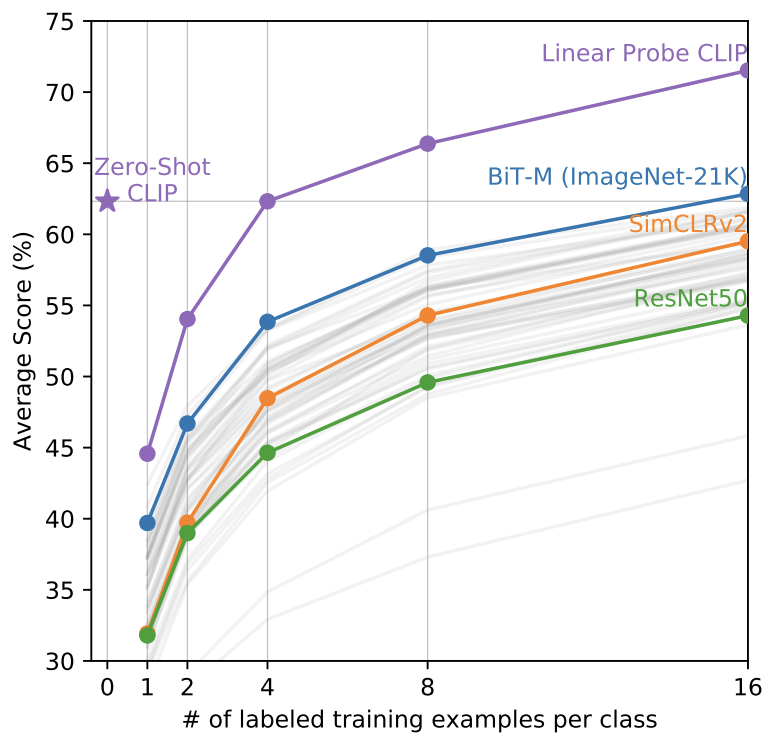
- fully supervised model과 비교한 것은 CLIP의 “task-learning capability”를 보여줄 수 있는 지표였다.
- few-shot learning(in Linear Probing)과 비교하는 것이 CLIP의 성능을 측정하는 더 직접적인 지표이다.
- 위의 그래프에서 확인할 수 있듯, 다른 모델들보다 CLIP의 zero-shot이 더 월등한 성능을 보였다.
- 다만, CLIP에서 오히려 one-shot prediction의 성능은 zero-shot보다 낮았다. CLIP에서는 4-shot 이상부터 zero-shot과의 성능이 동등했다.
- 이는 zero-shot과 few-shot의 학습에 대한 접근 방식의 차이에서 온 것으로 보여진다. (자세한 내용 생략).
2. Linear Probing
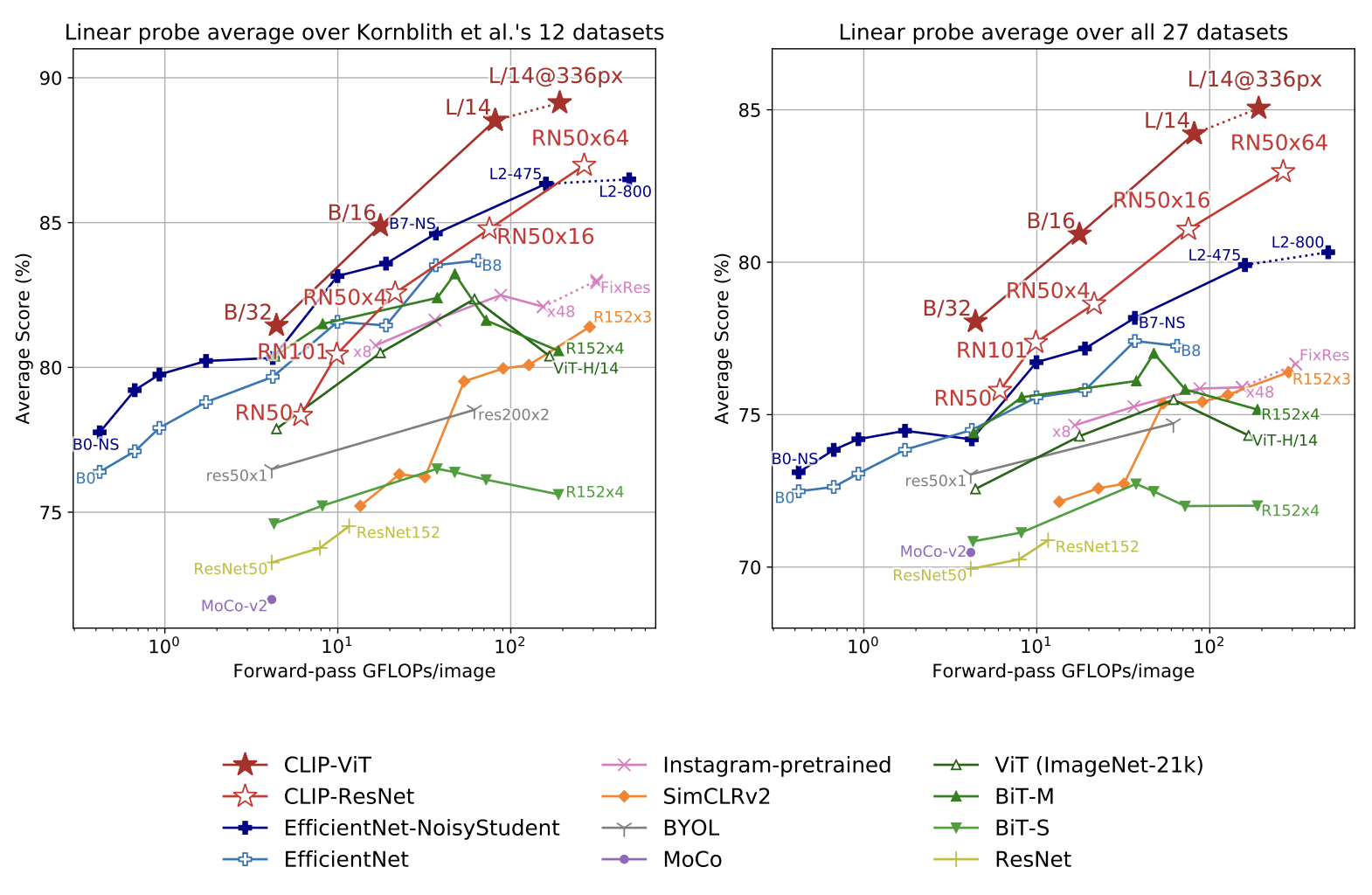
- model에서 학습된 feature extractor에, linear classifier를 붙여 다양한 dataset에 대해 성능을 측정하는 것이 국룰이다.
(Fitting a linear classifier on a representation extracted from the model and measuring its performance on various datasets is a common approach.) - 위에서 볼 수 있듯, 그러한 Linear Probing 테스트에서도 다른 모델들보다 더 좋은 성능을 보였다.
3. Robustness
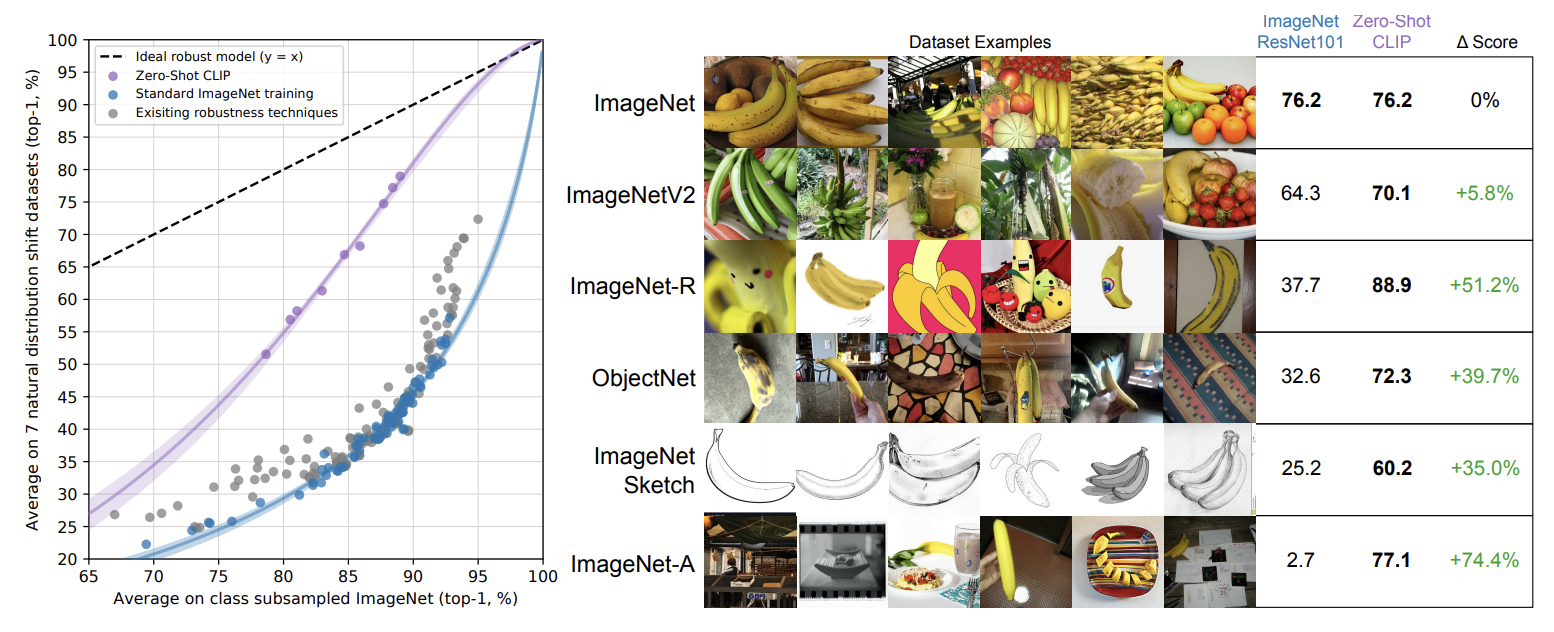
- Natural Distribution Shift dataset에 대해서도, 다른 표준 ImageNet 모델들보다 더욱 월등한 성능을 보인다.
- ImageNetV2, ImageNet Adversarial과 같은 7개의 dataset에서 테스트하였다.
- 기존에, synthetic distribution shifts된 data에 대해서는 성능을 향상시키는 방법이 부분적으로는 연구되었으나, Natural distribution shift에 대해서는 충분한 개선사항을 보이지 못했다. 그러나 CLIP은 이 부분에 대해 상당한 성능 향상을 보였다.
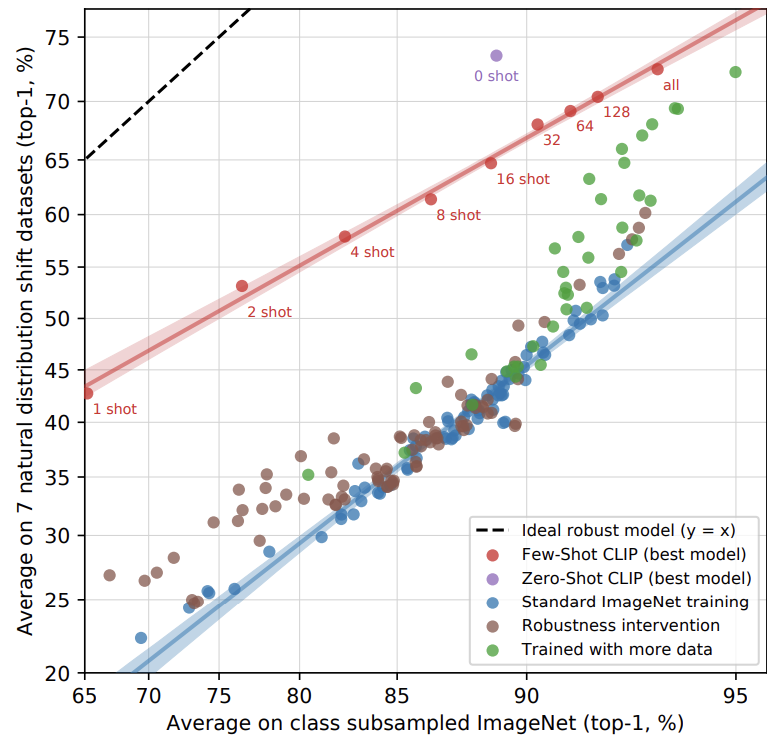
- Zero-shot CLIP은 이러한 Robustness를 향상시켰으나, 위의 그래프에서 fully supervised learning의 환경에서는 이러한 robustness에 대한 향상점이 거의 희미해진다는 것을 보여준다.
Reference
Learning Transferable Visual Models From Natural Language Supervision
코드 Repository
https://github.com/openai/CLIP
논문 리뷰 영상 (간단한 개요만 설명)
[논문 리뷰] CLIP (Learning Transferable Visual Models From Natural Language Supervision) - 김보민
위 영상의 reference 블로그 (한국어)
https://greeksharifa.github.io/computer vision/2021/12/19/CLIP/
논문 리뷰 블로그 (한국어)
CLIP 논문 리뷰 - Learning Transferable Visual Models From Natural Language Supervision
논문 리뷰 영상2 (DSBA연구실)
[Paper Review]Learning Transferable Visual Models From Natural Language Supervision | CoOp | Co-CoOp