Reference
https://iai.postech.ac.kr/teaching/machine-learning
https://iai.postech.ac.kr/teaching/deep-learning
위 링크의 강의 내용에 기반하여 중요하거나 이해가 어려웠던 부분들을 정리하여 작성하였고,
모든 강의 슬라이드의 인용은 저작권자의 허가를 받았습니다.
또한, 모든 내용은 아래 Notion에서 더 편하게 확인하실 수 있습니다.
>>노션 링크<<
Keywords
- Convolutional Autoencoder (CAE)
- Transposed Convolution
Convolutional Autoencoder

Motivation: 이미지는 어떻게 Autoencoder에 적용시킬 것인가?
Autoencoder의 목적이란 → Input을 Output에 copy시키는 것. 그렇게 학습을 진행한다.
그런데 기존의 Autoencoder로는 이미지를 Flatten시켜 encoding하는 과정에서, 정보 손실이 많이 일어날 것. 따라서 Convolution을 이용해 input을 Original Space에서 Latent Space로 옮기도록 학습한다면, regional information에 대한 loss를 줄일 수 있을 것이라는 아이디어.
(결과적으로, Convolution이 들어간 Autoencoder일 뿐.)
Convolution 과정에서 Max pooling 등을 수행하기 때문에, downsampling은 비교적 자연스럽게 수행되어질 수 있다.
그러나 upsampling은 1x1의 값을 3x3으로 만든다고 생각하면.. 쉽지 않은 작업이 될 것이다.
그러므로 CAE의 핵심은, 어떻게 upsampling(convolution의 반대 행동)을 더 자연스럽게 수행할 수 있는가. → transposed convolutional layer!

transposed convolutional layer에서 어떻게 upsampling을 수행하는 지 보여주는 예시이다.
위와 같은 형태로 padding을 넣어 output이 원하는 형태로 나오도록 하고, convolution을 수행하는 과정은 동일하다.

또한 stride가 조금 다른 의미인 것에 대해 확인하자.
Transpose Convolution에서 stride는 Kernel swipe 시 움직이는 칸 수가 아닌, input이 떨어져 있는 칸 수라고 생각하면 될 것 같다.
swipe는 항상 한 칸씩 수행하게 된다. 그럼 왜 stride인가- 라고 생각된다면, 여기서의 stride는 input과 output을 뒤집어놓고 생각했을 때, stride 2로 수행하면 그러한 결과가 나와서라고 생각하면 좀 더 이해가 쉬울 것이다.
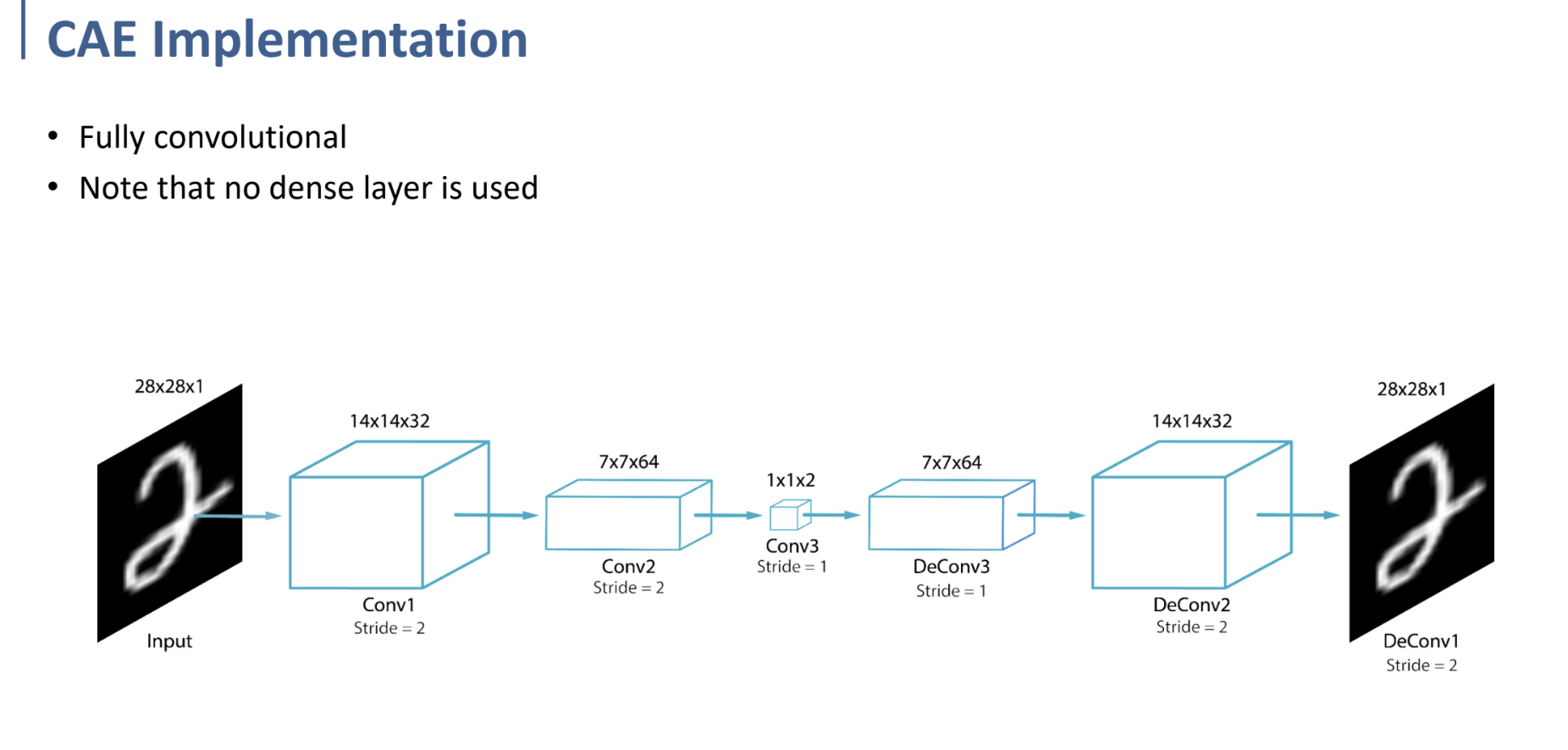

최종적으로 이런 형태로 Convolution을 수행하여 Original Space에서 Latent Space (1x1x2)까지 encoding을 수행하고, Transpose convolution을 반대 순서로 수행하여 다시 원래의 형태로 돌려놓는 것을 목표로 한다.