Reference
https://iai.postech.ac.kr/teaching/machine-learning
https://iai.postech.ac.kr/teaching/deep-learning
위 링크의 강의 내용에 기반하여 중요하거나 이해가 어려웠던 부분들을 정리하여 작성하였고,
모든 강의 슬라이드의 인용은 저작권자의 허가를 받았습니다.
또한, 모든 내용은 아래 Notion에서 더 편하게 확인하실 수 있습니다.
>>노션 링크<<
Keywords
- GAN - Idea
- GAN - Intuition, Mechanism
- GAN - Loss Function
Generative Adversarial Networks (GAN) - Idea
앞 장에서까지는, $p_{model}$과 $p_{data}$를 구하여, 그 사이의 loss를 minimize하는 방식으로 Network를 학습하는 방법으로 접근하였다.
그러나 여기서부터 설명할 GAN은, Generative Model을 학습하는 것에 대해 다른 방법으로, 어떤 explicit한 density function을 이용하지 않는 방식으로 접근할 것이다. (예를 들면, gaussian distribution, uniform distribution과 같은 분포를 이용하지 않겠다는 말이다.)
결국 어떻게 density function을 approximate할 것인가는 변하지 않는다

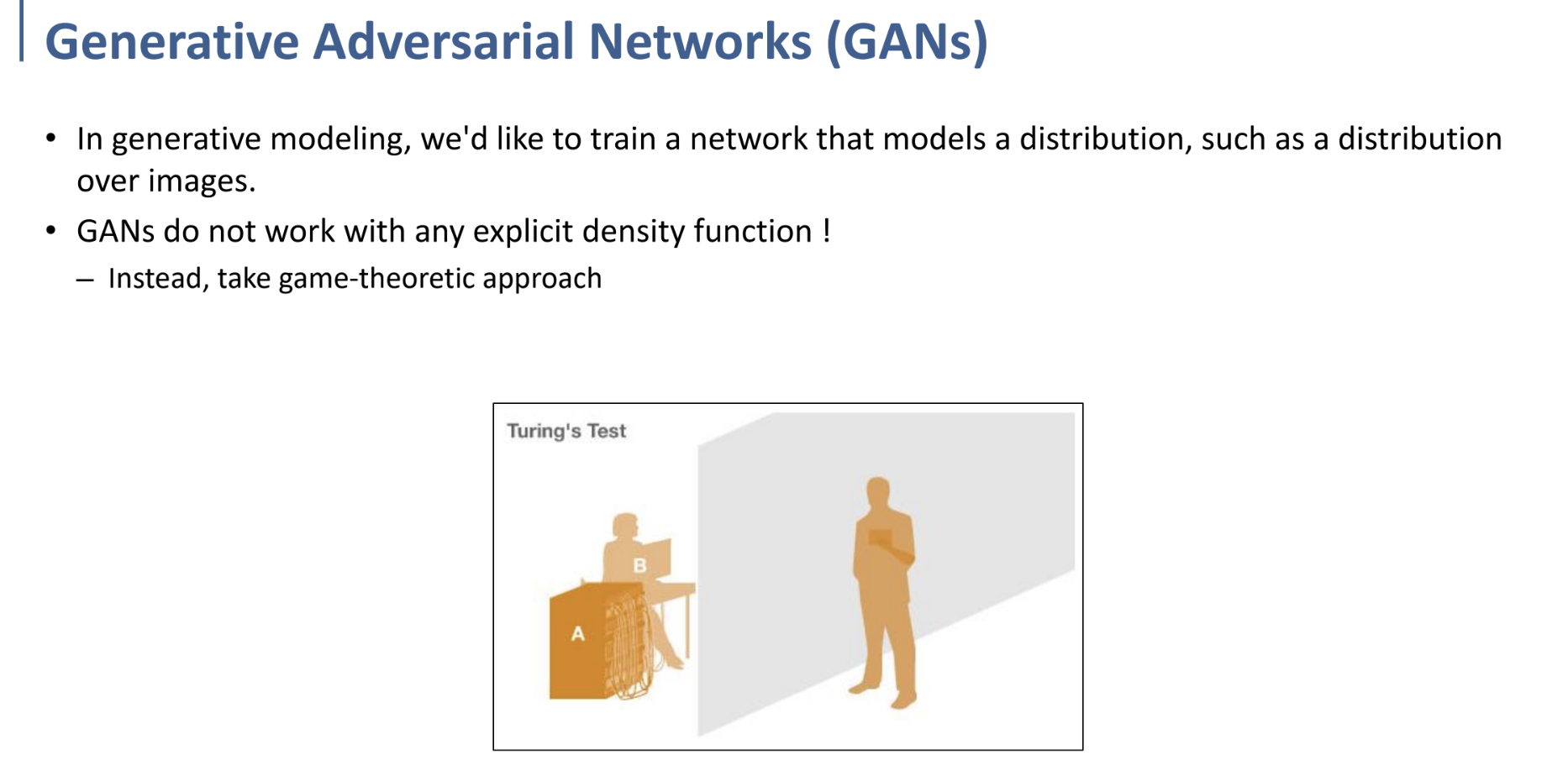
여기에서 Turing test의 아이디어를 차용한다.
Model에 의해 생성된 sample이, discriminator에 의해 판단했을 때 real data와 무엇이 진짜이고 가짜인지 구별할 수 없다면, 결국 그 generative model의 density function(PDF)가 data의 PDF에 approximate된 상태이지 않겠느냐~ 라는 것이다.
앞에서는 Distribution에 대해 집중하며, 그 data를 generate해내는 과정 자체를 살펴보며 optimization을 수행했다면,
GAN에서는 그 과정을 보는 것이 아니라, 결국 그 결과가 구별할 수 없다면 PDF 자체도 approximate된 것이 아니겠느냐 라고 바라보는 것.

그래서, GAN에서는 2개의 Network를 학습하게 된다.
Generator Network에서는 real data와 비슷한 sample을 만들어내도록 학습할 것이고,
Discriminator Network에서는 real data와 fake data를 잘 구분하도록 학습할 것이다.
결국 discriminator는 generator가 생성한 data가 real인지 fake인지 더 잘 구분하도록 계속 학습하고,
generator는 그러한 discriminator가 fake data를 구분할 수 없도록 real data와 더 유사한 것을 생성하도록 계속 학습하며 서로 학습을 반복하게 된다.

그래서, 결론적으로는 위 형태의 Network 2개를 학습하게 되는 것이다.
Generator에서 Generate된 Output이 Discriminator에서의 Input으로 들어갔을 때, Discriminator가 Real로 판단하도록 학습할 것이며,
Discriminator에서는 Generate된 data는 fake로, Real data는 real로 구분할 수 있도록 학습할 것이다.
GAN - Intuition, Mechanism
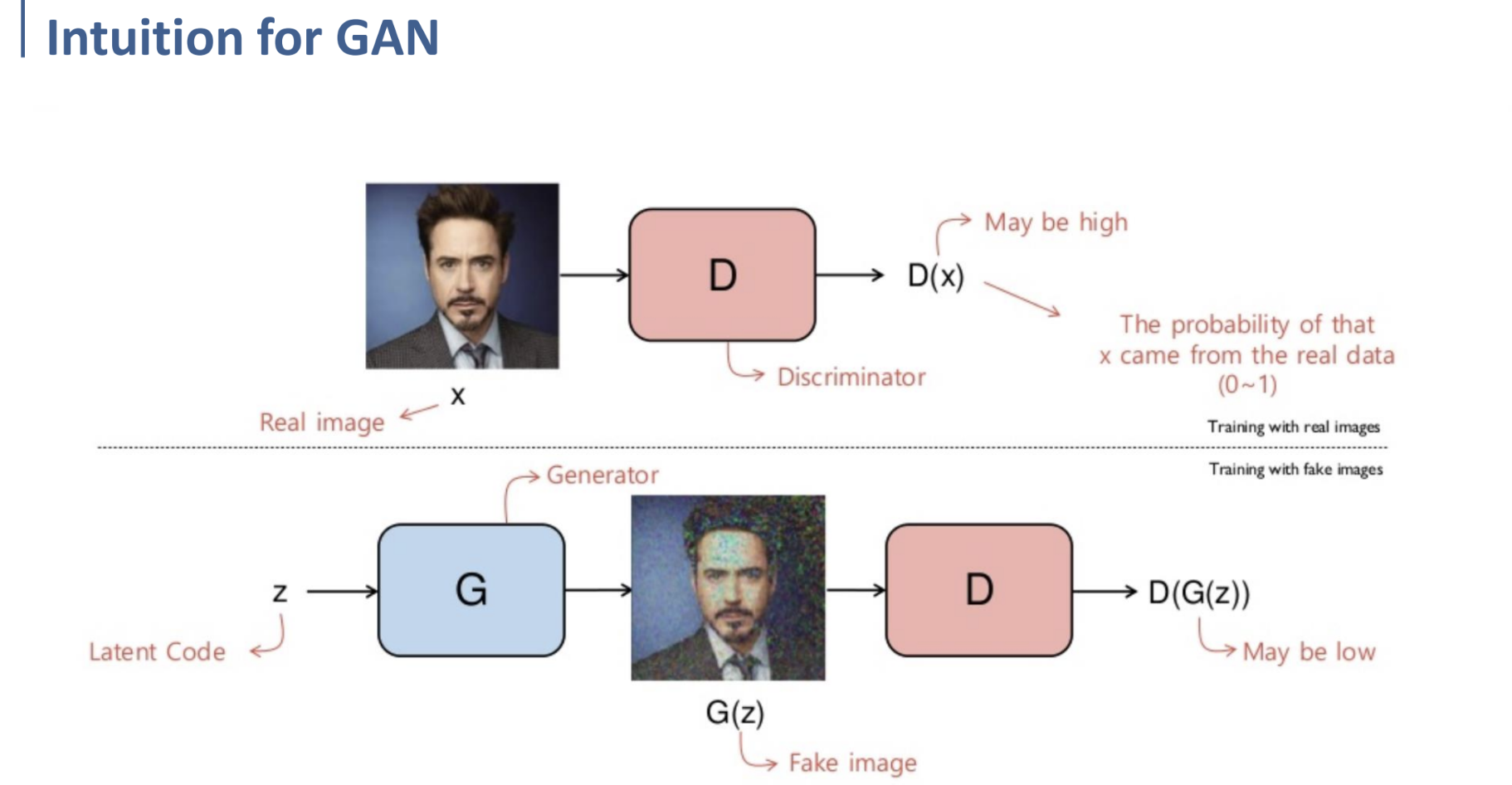
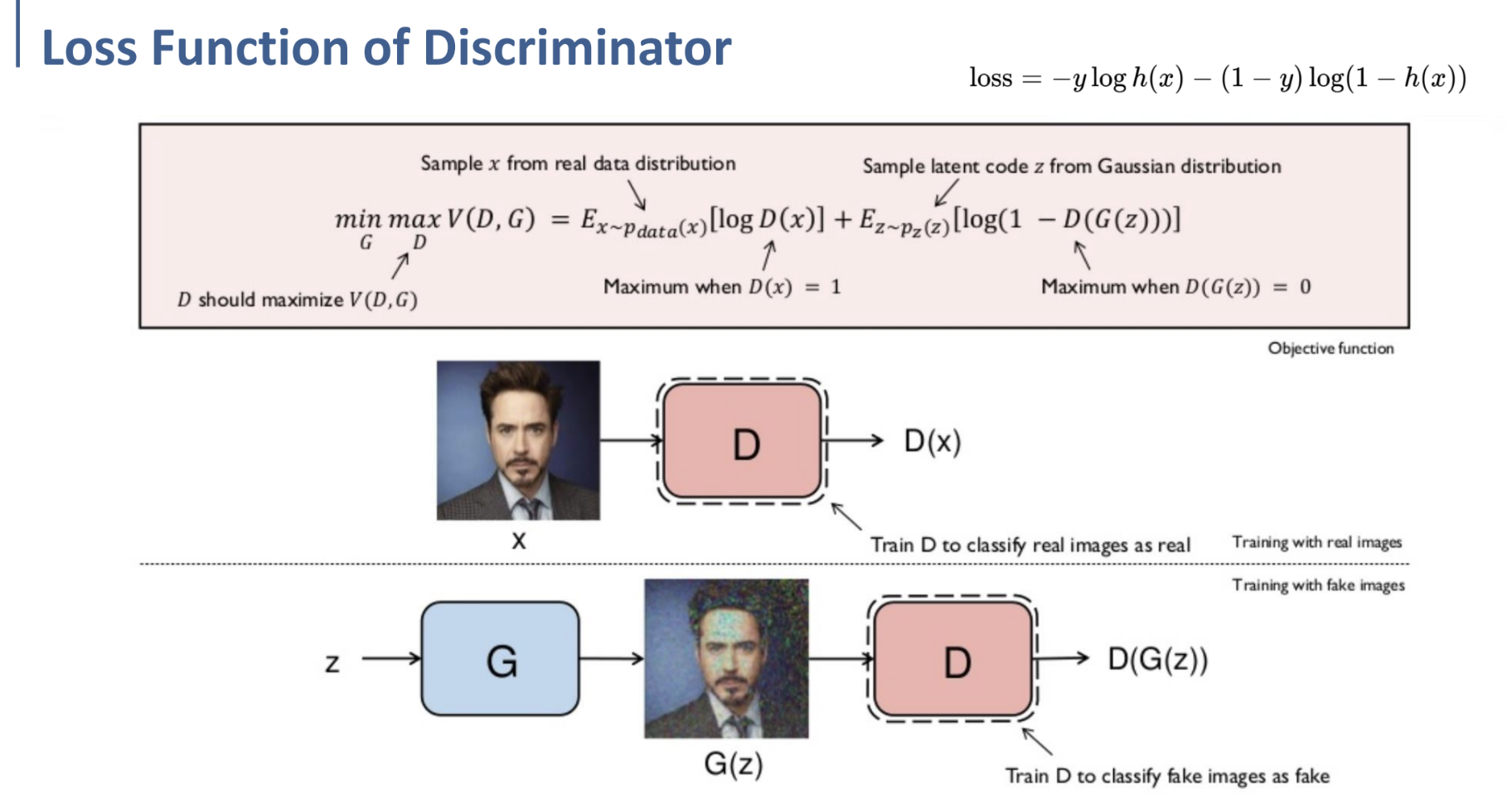
위와 같이, GAN의 학습 과정은 real image에 대해 학습시키는 것과 fake image에 대해 학습시키는 것으로 나누어 볼 수 있다.
이 때 Discriminator와 Generator는 각각 별개의 Neural Network이고, 각각 별개의 Network로써 학습된다.
그러므로 우선 Discriminator의 관점에서 학습 과정을 살펴보자.

Discriminator의 관점에서, real image $x$가 input으로 들어오면, Discriminator는 이를 real로 classify해야 한다.
다시 말해, Discriminator $D$를 거친 real image $x$의 값, $D(x)$가 real image로 classify되도록 (그 값이 1에 가까워지도록) 학습해야 한다는 것이다.
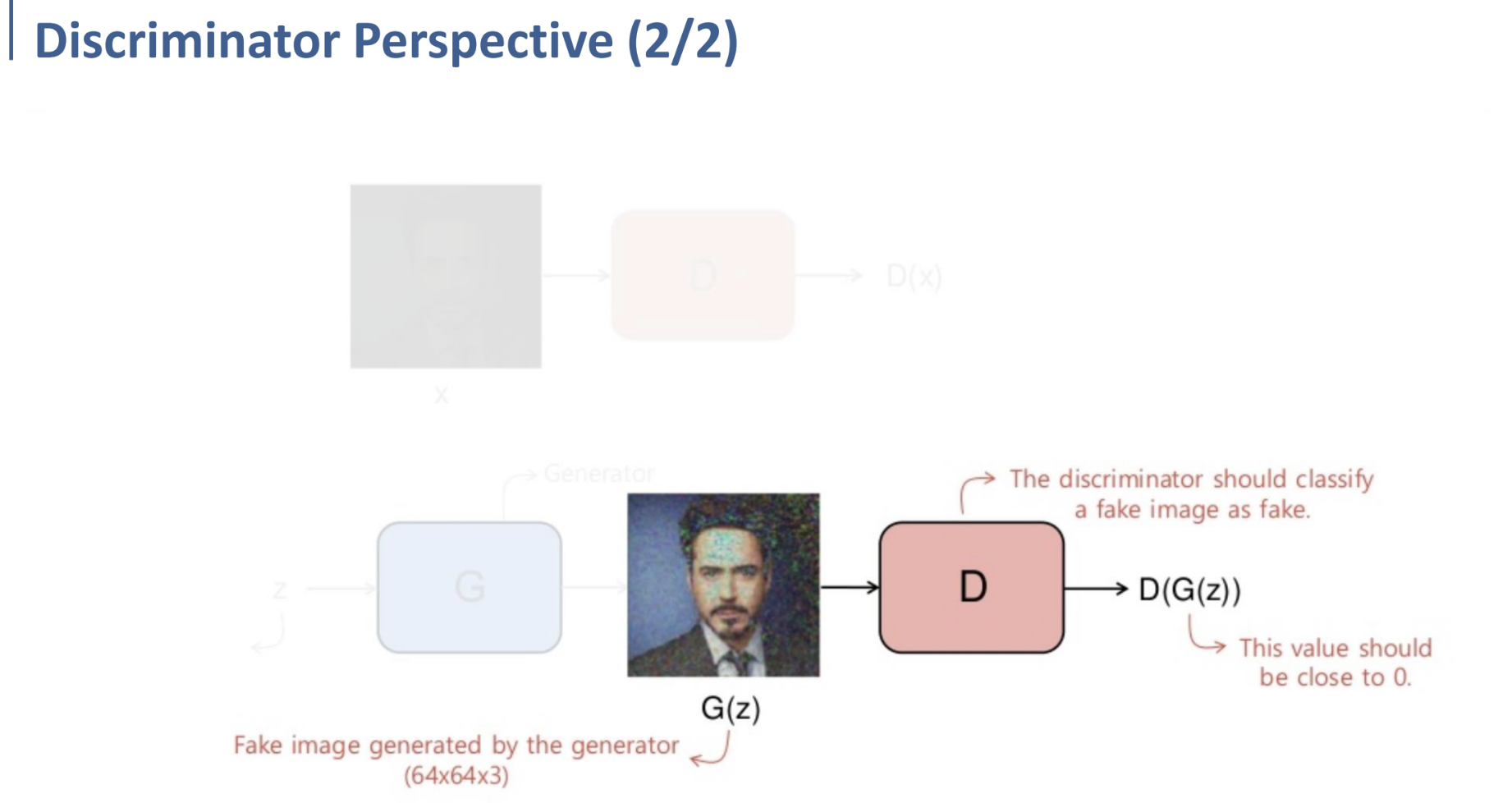
반대로 Generator를 통해 들어온 fake image $G(z)$가 input으로 들어오면, Discriminator는 이를 fake로 classify해야 한다.
Latent Space (Latent Code)인 $z$가 Generator를 거쳐 생성되는 fake image의 값이 $G(z)$이다.
여기에서는 반대로, Discriminator $D$를 거친 fake image $D(G(z))$가 fake image로 classify되도록, $D(G(z))$의 값이 0에 가까워지도록 학습해야 한다.
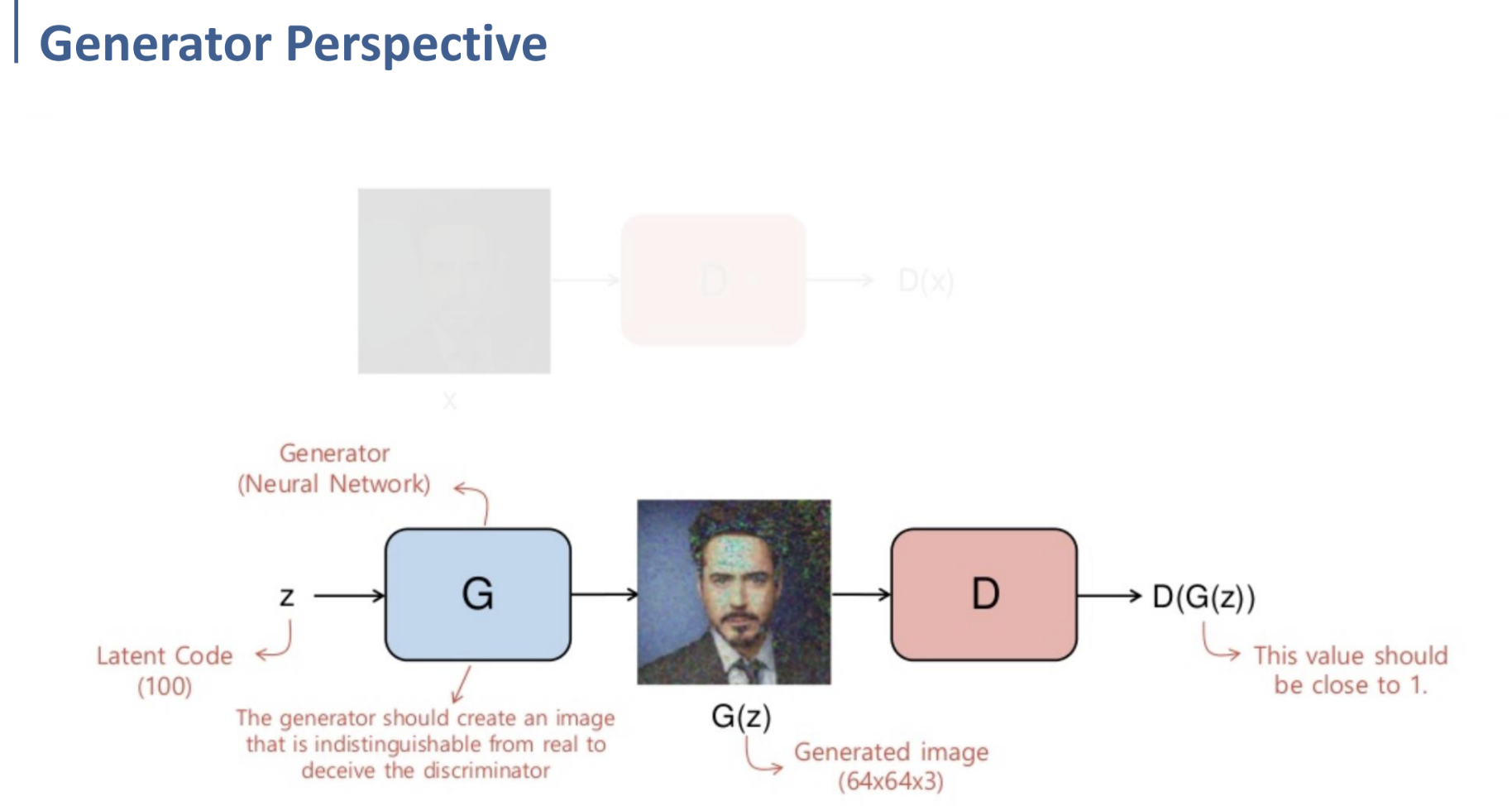
다음으로는 Generator의 관점에서 학습 과정을 살펴보자.
Latent Code $z$가 Generator를 통해 fake image $G(z)$를 생성하게 되는데,
그 과정에서 Generator는 이렇게 생성된 이미지를 Discriminator가 real image로 판별하기를 원한다.
따라서, 이 경우에는 $D(G(z))$의 값이 1에 가까워지도록 학습해야 하는 것이다.
Discriminator, Generator 입장에서 학습해야 하는 이러한 방식들을, Loss Function으로 어떻게 정의할 수 있는지 아래에서 살펴보자.
GAN - Loss Function
Logistic Regression에서의 BCE(Binary Cross Entropy), 그리고 log likelihood를 상기하자.
GAN를 학습하는 데에 사용할 Loss Function은 다음과 같다.
$\underset{G}{min} \ \underset{D}{max} V(D, G) = E_{x \sim p_{data}(x)} [ \log D(x)] + E_{z \sim p_z(z)} [\log (1 - D(G(z)))]$
이 식을, Discriminator의 입장에서만 보도록 하자.
( $\underset{D}{max}$ - Discriminator 관점에서는, 전체 식을 maximize하도록 한다.)
우선 $E_{x \sim p_{data}(x)}$ 에서의 $x \sim p_{data}(x)$는 $x$ 가 real data distribution에서 sampling되었다는 것을 의미하고, (real data)
$E_{z \sim p_z(z)}$ 에서의 $z \sim p_z(z)$ 는 $z$ 가 Latent code인 Gaussian distribution에서 sampling되었다는 것을 의미한다. (fake data)
Discriminator의 입장에서 보면,
$E_{x \sim p_{data}(x)} [ \log D(x)]$ 에서, $x$ 는 real data distribution에서 sampling된 $x$이므로, $D(x)$가 1이 되도록 해야 한다. ($D(x)=1$ 일 때, $E_{x \sim p_{data}(x)} [ \log D(x)]$ 의 값이 maximize되므로.)
$E_{z \sim p_z(z)} [\log (1 - D(G(z)))]$에서는, $x$ 가 Latent code에서 sampling된 $x$이므로, $D(G(z))$가 0이 되도록 해야 한다. ($D(G(z))=0$일 때, $log$ 안의 값이 1이 되므로, maximize.)

다음으로는 이 식을, Generator의 입장에서 보도록 하자.
( $\underset{G}{min}$ - Discriminator 관점에서는, 전체 식을 minimize하도록 한다.)
우선 앞의 항은 Generator 입장에서는 Independent하므로 (G와 아무런 연관이 없고, 영향을 주지 못하므로), 신경쓸 필요가 없다.
뒤쪽 항인 $E_{z \sim p_z(z)} [\log (1 - D(G(z)))]$ 만 minimize하면 되는 것인데, 이 항을 minimize한다는 것은, $D(G(z)) = 1$ 으로 만들겠다는 것이다.
⇒ 결국, Generator를 통해 생성한 fake image를 Discriminator가 real image로 인식하도록 해야 한다는 것.
종합하면, 전체 loss function이 정의되었으며, Discriminator를 학습할 때에는 Generator에 관련된 것들은 fix한 채로 전체 식을 maximize할 것이고, Generator를 학습할 때는 Discriminator에 관한 것들을 fix하고 전체 식을 minimize할 것이다.