* 이 시리즈의 마지막 글입니다. *
Reference
https://iai.postech.ac.kr/teaching/machine-learning
https://iai.postech.ac.kr/teaching/deep-learning
위 링크의 강의 내용에 기반하여 중요하거나 이해가 어려웠던 부분들을 정리하여 작성하였고,
모든 강의 슬라이드의 인용은 저작권자의 허가를 받았습니다.
또한, 모든 내용은 아래 Notion에서 더 편하게 확인하실 수 있습니다.
>>노션 링크<<
Keywords
- Long Short Term Memory (LSTM)
Long Short Term Memory (LSTM)
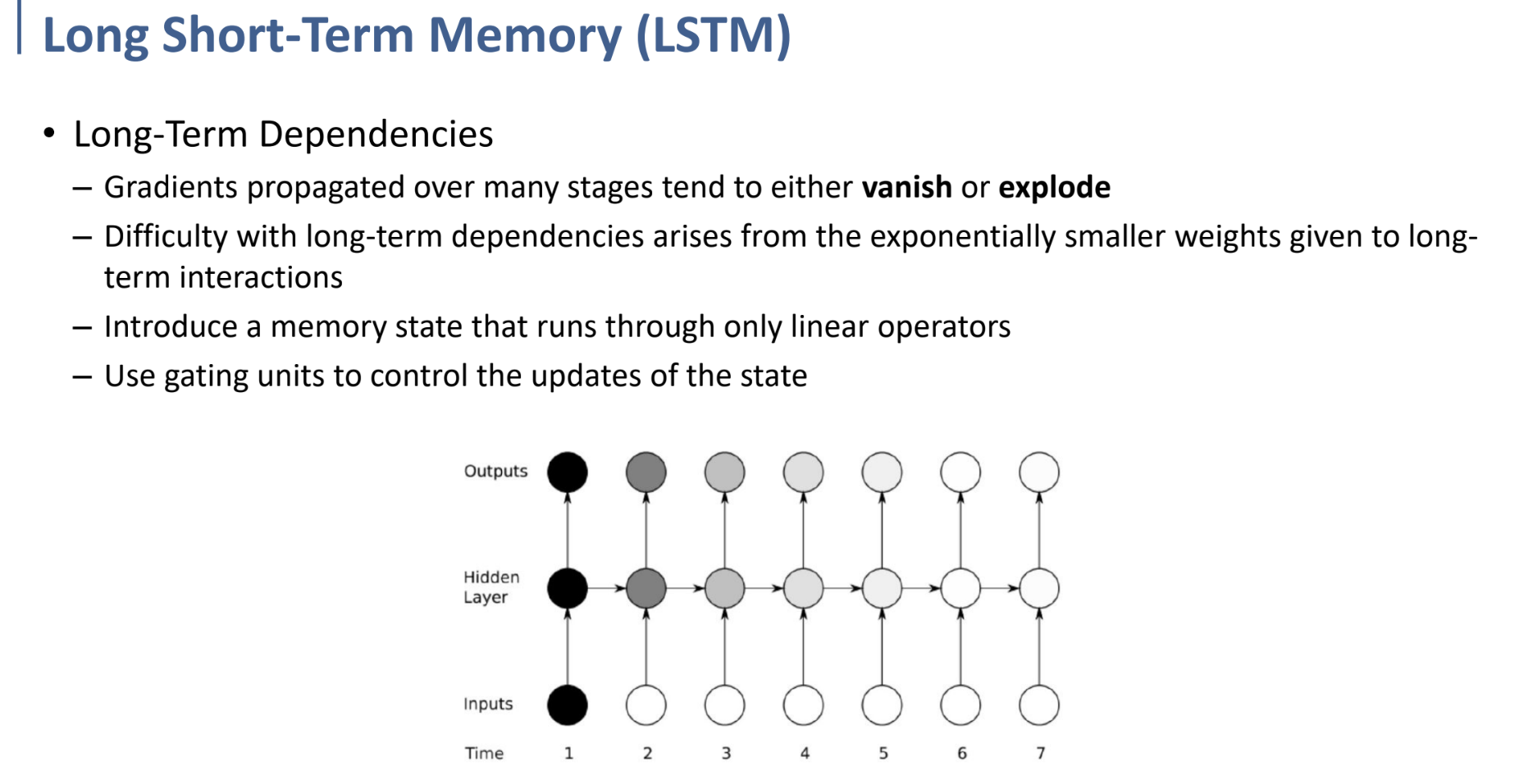
RNN에서, 많은 stage를 거칠 수록 결국 gradient가 vanish되거나 explode되는 경향은 발생한다.
또한 long-term을 다룰 때, 긴 시간 이전의 데이터에 대한 영향은 갈수록 거의 미미해질 수밖에 없다.
이 문제에 대해, 물론 physical한 어떤 시계열 데이터를 다룬다면, 당연히 지금으로부터 과거의 데이터일수록 영향이 줄어드는 것이 이치에 맞을 것이다.
그러나 만약, 문장을 번역한다던가 하는, 글에 대한 시계열 데이터를 다룰 때는, 멀리 있는 단어일지라도 현재 단어에 영향을 significant하게 주어야 할 수도 있는 것이다. 그렇기 때문에 이것이 문제라는 것.
이러한 문제들을 해결하기 위해, state를 “memory”하는 개념과, “gating unit”을 사용하는 LSTM이 고안되었다.

gating unit
우선 각 unit에 대해 gate를 만든다고 생각하면 쉬울 것 같다.
information이 흘러가는 것을 막을 지, 막지 않을 지를 같이 학습하게 되는 것이다.
막는 것을 0, 흐르게 하는 것을 1이라고 하면, sigmoid function으로 감싸 0~1 사이의 값으로 바꾸면 학습이 가능하게 될 것.
예를 들어 위와 같은 경우, gate의 상태에 따라 time 1에서의 input information이 time 4의 output까지 적은 loss로 흘러간다는 것이다.

위의 그림이 LSTM Cell이다. (RNN이였으면, 단순히 하나의 time에서 하나의 Neural Network였을 cell.)
위 구조를 차근차근 뜯어보며, 지금부터 위 cell에 대해 설명할 것이다.
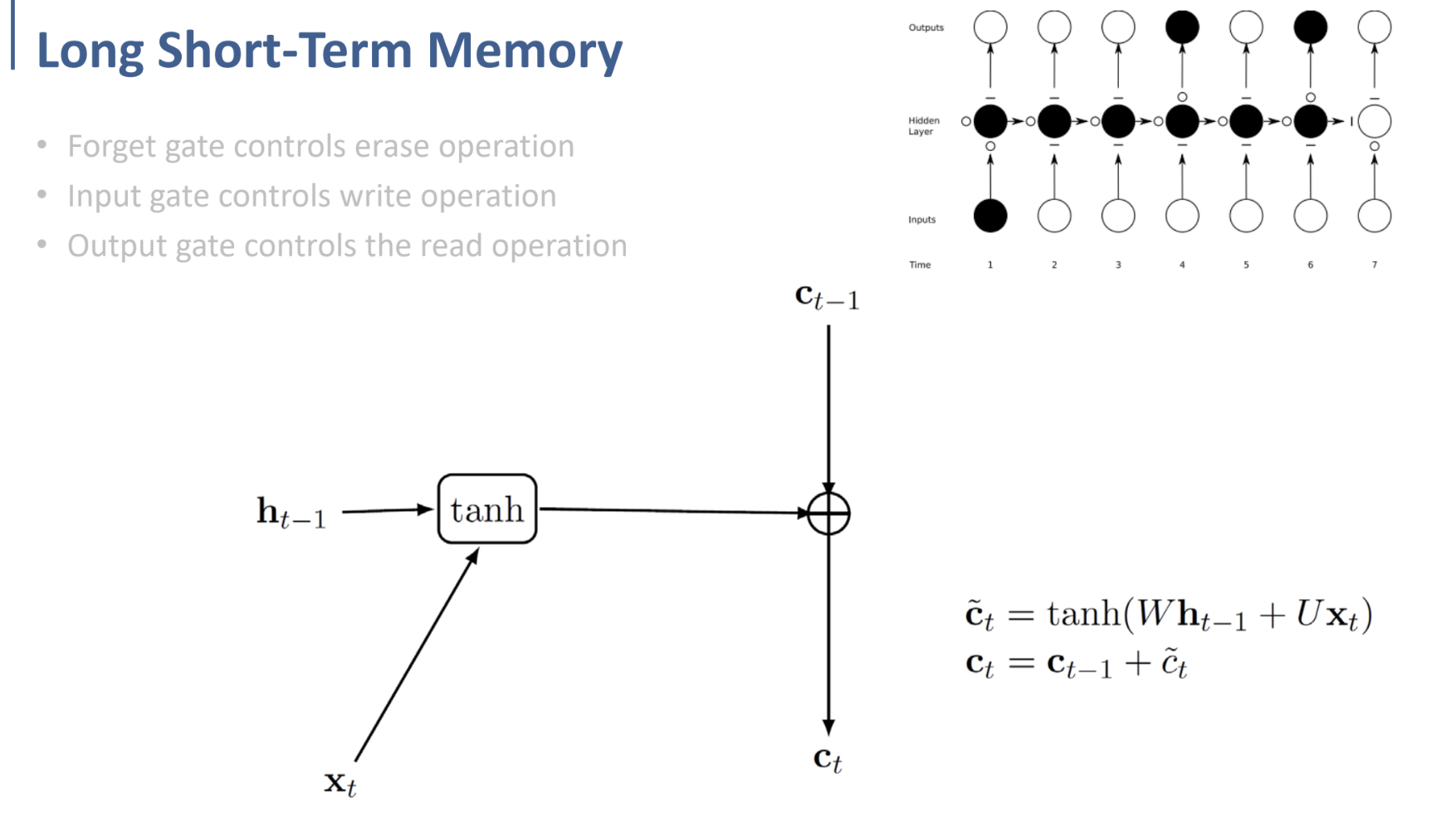
먼저 cell을 들어오고 나가는 정보부터 보자면, $x, h$ 는 원래 RNN에서와 마찬가지로 input, state이다.
또한 $C$는 바로 이전에서 설명한, LSTM에서의 gate이다.
그리고 $i, f, o$는 각각 input, forget, output gate에 관련된 것임을 알 수 있다.
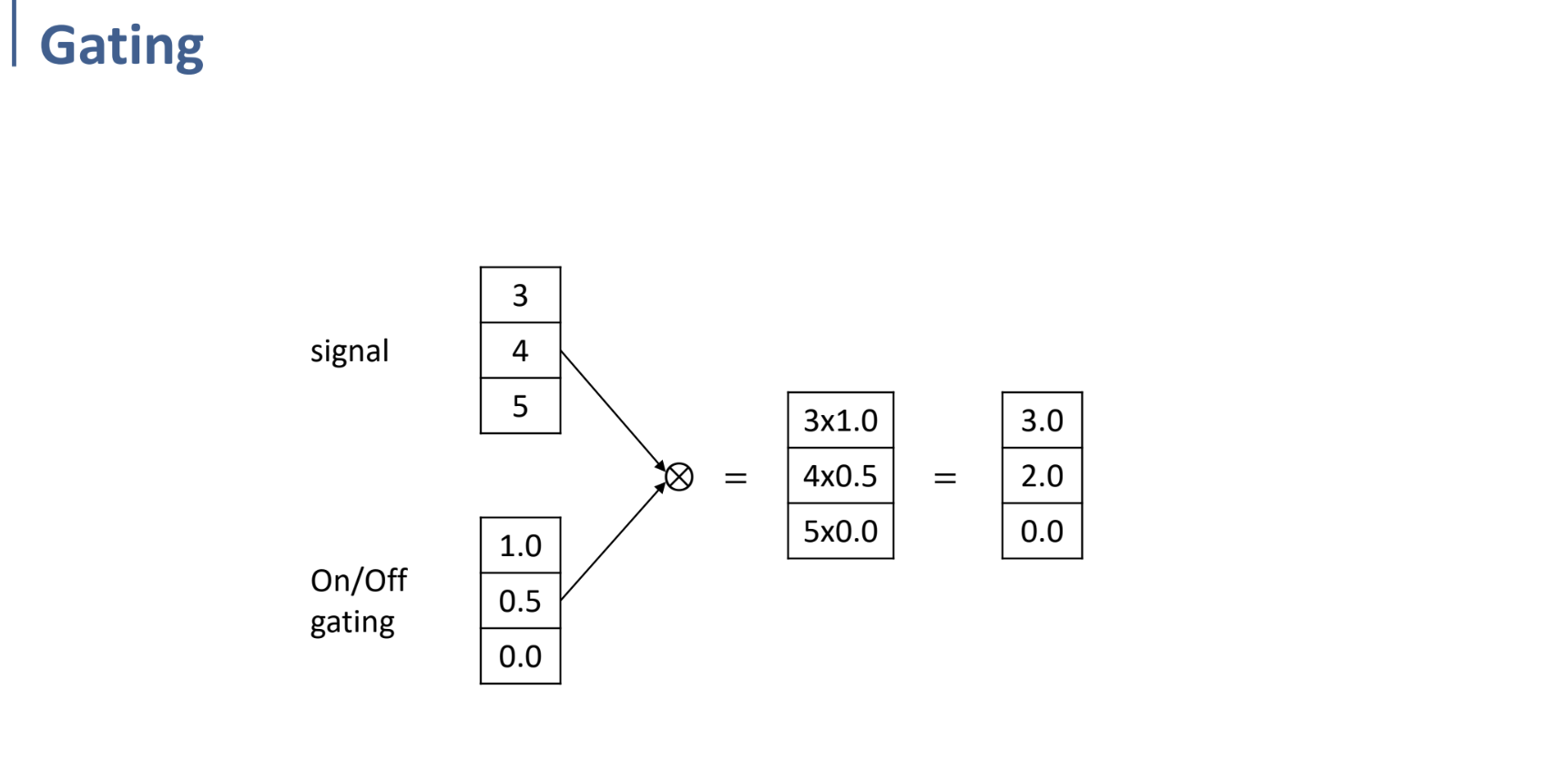
우선 gate를 이해하기 위해, gating이 어떻게 동작하는지부터 확인하자.
위와 같이 gate와 input을 element-wise multiplication하는 식으로 작동한다.

그리고 여기서부터, LSTM 내부가 어떻게 동작하는지 설명한다.
예시를 들어, 오늘 저녁 메뉴를 prediction 해야한다고 생각해 보자.
이를 prediction하기 위해, 현재의 observation(dinner yesterday)와 과거 state(predictions for yesterday)를 이용할 것이다.
여기까지는 앞에서 봐 왔던, $h_t = f(x_t, h_{t-1})$ 이다.

위의 예시를 좀 더 구체화하고, RNN 구조를 다시 도식화하면 다음과 같은 형태일 것이다.
이제 이 형태에서, LSTM을 구현하기 위해 곳곳에 gate를 달기 시작한다.

각 ignoring, forgetting, selection을 담당하는 gate들이 추가된 최종 LSTM cell의 형태는 다음과 같다.
ignoring(input) gate에서는 새로운 정보들 중 어떤 것들을 cell state에 저장할 지 취사선택한다.
forgetting gate에서는 state의 정보들 중 필요 없는 것들을 버린다.
마지막으로 selection(output) gate에서는 어떤 것들을 output으로 내보낼 지 결정한다.