![[논문 리뷰] BLIP (Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FFjoFI%2FbtsMrYO5MBM%2FAAAAAAAAAAAAAAAAAAAAAKhMcrDh9vnen6LIPIvBIW9EjwNlG4LwvqbPxeR-I9na%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3Dt8CUi681dFj19NL00UaPXUZr1Bw%253D)
[딥러닝 논문 리뷰 시리즈]
노션에서 작성한 글을 옮겼으며, 아래 노션에서 더 깔끔하게 읽으실 수 있습니다.
BLIP (Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation) | Notion
Reference
skillful-freighter-f4a.notion.site
Abstract & Introduction
Background, Motivation
- Vision-Language Pre-training(VLP)은 대규모의 Image와 Text pair를 통해, 모델이 여러 Vision-Language task(Image-text Retrieval, Image Captioning, VQA, …)에 활용될 수 있도록 pre-train하는 기법이다.
- 하지만 기존의 많은 VLP 접근들은 “이해 기반(understanding-based)” 혹은 “생성 기반(generation-based)” 둘 중 하나에만 강점이 있었다. 예를 들어, CLIP(Radford et al., 2021) 같은 모델은 Image-text matching, Retrieval과 같은 understanding-based task에는 뛰어나지만, text를 직접 생성(Image Captioning 등)하는 task에는 활용하기 어렵다는 한계가 있었다.
- 또한, 최근에는 웹에서 수집한 대규모의 image-text pair를 통해 pre-train을 수행하는 경우가 많았다. 이 데이터에는 noise가 많이 들어가 있었으나, Dataset의 규모 확장으로 인해 얻는 성능의 향상에 비하면 작은 수준이었기에 noise에 의한 부정적 영향 자체가 간과되고 있었다.
논문(BLIP)의 Main Contribution
- Model Perspective: 하나의 모델에서 이해(understanding)와 생성(generation)을 모두 수행할 수 있도록, Multimodal Mixture of Encoder-Decoder(MED)라는 새로운 구조를 제안한다.
- Data Perspective: noise가 많은 image-text pair data를 그대로 쓰지 않고, CapFilt라는 새로운 bootstrapping 방식을 이용해 데이터 품질을 개선한다.
- Captioner: 웹 image에 대해 synthetic text를 생성.
- Fliter: 원본 text, 생성된 text가 image와 부합하는지 판별하여 noise 제거.
- 이러한 구조를 가진 BLIP framework를 통해 다양한 downstream task에서 SOTA(State-of-the-Art)에 준하거나 뛰어넘는 성능을 달성하였다.
Model: Multimodal Mixture of Encoder-Decoder (MED)
기존 접근방식의 한계
- Encoder-only 모델(e.g., CLIP, ALBEF)은 Image-Text Matching(Retrieval)이나 Classification, Retrieval 등 understanding-based task에는 적합하지만, autoregressive한 text generation을 수행하기 어렵다.
- Encoder-Decoder 모델(e.g., VL-T5, SimVLM)은 text generation task에는 유리하지만, image-text retrieval 같은 task에서 encoder만 사용하기에는 구조가 비효율적이거나 충분한 성능이 나오지 않을 수 있다.
Autoregressive Text Generation: 간단하게는, 이전의 token들을 기반으로 확률적으로 가장 높은 다음 token을 예측하며, linear하게 text를 생성해내는 과정이라고 보면 된다.

MED의 핵심 설계
본 논문에서는 위와 같은 한계점을 해결하고자, 아래 3가지 기능(모듈) 중 하나를 실행할 수 있는 multi-task model을 제안한다.
하나의 통합된 Architecture에서, 학습 시에는 세 유닛 모두가 각각의 Loss를 통해 동시에 학습되며, Inference 시에는 세 가지 유닛(기능) 중 하나가 downstream task에 따라 선택적으로 activate되는 것.
- Unimodal encoder
- Image는 ViT로 Embedding, Text는 BERT의 text encoder로 embedding한다.
- 이 때 Image, Text 각각의 vector embedding을 얻는다. (즉, image-text 간의 Cross-Attention을 수행하지 않는다.)
- 주 목적: 이미지-텍스트 간 전반적인 feature space 정렬(contrastive alignment).
- Image-grounded text encoder
- Text encoder의 각각의 transformer block 내부에, Self-Attention(SA) layer와 Feed-Forward Network(FFN) 사이에
Cross-Attention(CA)layer를 추가한다. 이를 통해 Image에서 뽑아낸 Vision embedding과 text간 상호작용을 학습한다. - 문장 앞에
[Encode]와 같은 task-specific한 special token을 넣어, 최종적으로[Encode]token의 embedding을 image-text multimodal representation으로 간주한다. - 주 목적: Vision-language의 정교한 alignment를 포함하는 image-text multimodal representation을 학습하여, 주어지는 image-text pair의 matching 여부를 판별하는 것.
- Text encoder의 각각의 transformer block 내부에, Self-Attention(SA) layer와 Feed-Forward Network(FFN) 사이에
- Image-grounded text decoder
- Text encoder의 Bidirectional Self-Attention layer를 Casual Self-Attention layer로 변경하여, Autoregressive한 text generation을 수행할 수 있도록 한다.
[Decode]token을 sequence의 시작으로,[EOS]token을 sequence의 끝으로 사용한다.- 주 목적: Image에 대한 text generation (Image Captioning, VQA와 같은 downstream task)
Casual Self-Attention: 일반적인 Bidirectional Self-Attention을 수행할 때는 앞뒤의 모든 input token을 고려하여 각 token의 representation을 학습. -> text understanding 수행.
Casual Self-Attention은 앞의(이전의) token만을 고려하여 현재 단어를 예측. 이후의 token은 모두 masking한 상태로 attention을 수행. -> autoregressive text generation 수행.
위 3가지의 모듈이 각각 개별적으로 나눠져 있는 것이 아니라, 하나의 통합된 모델로써 학습되며, task에 따라 특정 기능을 활성화하여 작동하는 것이다.
이 과정에서 text encoder, text decoder의 Embedding, Cross-Attention, Feed-Forward 등의 layer의 parameter를 서로 공유하고, Self-Attention layer만 서로 다른 parameter를 갖는다.
이런 방식이 학습에 있어서 효율도 좋고, 서로 다른 task에서 학습한 parameter가 시너지를 낸다.
Pre-training Objectives
본 논문에서는 Pretrain 시점에 3가지 Loss Function을 동시에 optimize한다. 한 개의 image-text pair에 대해 위 3개의 모듈을 모두 거쳐 학습하되, ViT(Image Encoder)는 계산 효율성을 위해 한 번만 거친다.
- Image-Text Contrastive Loss(ITC Loss)
- Unimodal encoder에서, Image, text embedding을 통해 Contrastive learning을 수행한다. 이를 통해 두 transformer(image, text)의 feature space가 잘 align되도록 한다.
- CLIP, ALBEF 등에서도 사용되었던 방식으로, cosine similarity(vector similarity)를 통해 positive pair간의 거리가 가까워지도록 학습한다.
- Image-Text Matching Loss(ITM Loss)
- Image-grounded text encoder에서, image-text multimodal representation이 vision-language의 alignment를 정밀하게 잘 수행하고 표현하였는 지를 학습하도록 한다.
- 이를 위해 image-text가 match되었는지, 아닌지를 예측하는 Binary Classification task로써 접근한다.
- ITC에서 전역(global) 레벨의 맞춤만을 본다면, ITM은 문장 레벨에서 더 세부적으로 두 입력이 실제 매칭된 것인지 학습한다.
- Contrastive 하나의 batch 내에서 가장 유사도 높은 음성 쌍(“hard negative”)에 대해 loss를 계산할 확률이 높도록 학습한다. (hard negative mining strategy)
- Language Modeling Loss(LM Loss)
- Image-grounded text decoder에서, image가 주어졌을 때 textual description(caption)을 generate하도록 학습한다.
- VLP에서 자주 사용되는 BERT류 MLM(Masked Language Modeling)을 쓰는 대신, 순방향 LM(causal LM)을 사용함으로써, 일반화 능력을 통해 visual information으로 caption을 생성할 수 있도록 한다.
- 이로써, Image Captioning이나 VQA 등의 text generation이 필요한 작업에서 높은 성능을 낼 수 있다.
Hard Negative Mining: 단순한 BCE(Binary Cross Entropy)를 사용하여 학습을 수행하게 되면, 중간에 loss optimization이 더 이상 진행되지 않을 수 있음. 따라서, 분류가 어려운 (similarity는 높으나, 실제로 negative pair인)sample이 training 시 더 많이 관여할 수 있도록 한다.
“Align before fuse: Vision and language representation learning with momentum distillation” (Li 등, 2022, p. 10) Li et al. (2021a) (Li 등, 2022, p. 3)
CapFilt: Bootstrapping Noisy Web Data
문제의식
- 웹에서 크롤링한 대규모 image-text pair의 개수는 매우 많지만, 텍스트(alt-text 등)가 실제 이미지를 제대로 서술하지 않거나 의미가 빈약한 경우가 상당히 많다.
- 기존에는 데이터가 많으면 모델이 “어느 정도 noise를 무시하고 학습한다”는 가정으로 단순 확대를 시도했지만, 여전히 noise가 성능 상 한계를 초래한다.

CapFilt 개념
BLIP는 Captioning and Filtering(CapFilt)이라는 방식으로, 노이즈가 포함된 웹 텍스트를 ‘bootstrapping’한다.
이는 두 모듈, Captioner와 Fliter로 이루어져 있으며, 둘 모두 Pre-trained MED model로 initialize하여 COCO dataset으로 finetuning되었다.
- Captioner(이미지 → 텍스트 생성):
- Captioner 모듈은 Image-grounded text decoder 기능으로 동작한다.
- LM loss로 image에 대한 text를 생성하도록 fine-tuning되었다.
- web Image(I_w)가 주어졌을 때, 하나의 image 당 하나의 caption을 generate한다. (synthetic caption, T_s)
- Filter(이미지 & 텍스트 → 노이즈 판별):
- Filter 모듈은 Image-grounded text encoder 기능으로 동작한다.
- ITC, ITM loss로 image가 text와 match하는 지에 대해 fine-tuning되었다.
- Captioner가 생성한 text(T_s) 또는 web text(T_w)가 실제 image와 match되는지(ITM)를 분류해 noise일 경우 걸러낸다.
- Captioner로 생성한 “synthetic caption” 중 Filter가 통과시킨 것 + 원래 웹 텍스트 중 Filter가 통과시킨 것 + 인간이 주석한 고품질 텍스트(예: COCO) → 이 모든 데이터(image-text pair)를 합쳐 새로운 “clean + augmented” 데이터셋을 만든다.
- 마지막으로, 이 bootstrapping된 데이터셋으로 새로운 모델을 다시 학습(Pre-train)하여 성능을 높인다.

성능 향상을 위한 세부 전략
- 논문에서는 Captioner가 문장 생성 시 Nucleus Sampling을 활용해, 더 다양성(diversity) 있는 캡션을 얻어내야 성능이 좋아진다고 보고한다.(deterministic 한 decode 방식을 사용하는 beam search보다 성능 향상, Table 2)
- Filter와 Captioner를 동시에 사용하면, noise text 제거와 함께 새로운 visual information이 반영된 문장까지 확보할 수 있다.
- Captioner, Filter 모두 pretraine된 MED를 COCO dataset으로 lightweight finetuning하여 추가 비용이 크지 않다.
- 여러 라운드를 반복하거나, 하나의 이미지에 대해 여러 캡션을 생성하는 등 추가적인 발전 가능성도 열려 있다.
- pre-training 시 text encoder와 decoder가 self-attention layer를 제외한 모든 parameter를 공유하는 것이 더 성능이 좋았다. [Table 3]
SA Layer의 paramter를 공유하는 것은 오히려 성능이 떨어졌다.
SA Layer가 encoding task / decoding task 각각의 특성을 가지고 작업을 수행하고 있기 때문.

Pre-train 시 Captioner와 Filter의 parameter를 공유하는 것 또한 오히려 성능이 떨어졌다.
Captioner에서 생성된 noise caption이 filter에 의해 잘 걸러지지 않은 것을 확인할 수 있었다. [Table 4]
Nucleus Sampling (Top-p Sampling): “The Curious Case of Neural Text Degeneration”, Holtzman et al., 2020 (Li 등, 2022, p. 5).
Experiments & Results
본 논문에서는 크게 다섯 가지의 대표적인 Vision-Language downstream task(Image-text Retrieval, Image Captioning, VQA, NLVR2, VisDial)에서 BLIP의 성능을 평가하고, 기존 SOTA 모델들과 비교한다. 또한 Video-text task(video QA, text-to-video retrieval)에 대해서도 Zero-shot 성능을 테스트한다.
1. Pre-training 설정
- Image Encoder: ViT-B/16 or ViT-L/16 (initialized from ViT, Pre-trained on ImageNet) - (Touvron et al., 2020; Dosovitskiy et al., 2021)
- 다만, 이 논문에서 나오는 모든 결과를 ViT-B를 사용한 BLIP 모델.
- Text Encoder: initialized from BERT_{\text{base}}(Devlin et al., 2019)
- epoch, lr, resolution 등의 세팅은 논문 참고. [4.1. Pre-training Details]
- Dataset: COCO+Visual Genome(약 21만장의 이미지, human-annotated.), SBU, CC3M, CC12M(약 1400만장 이미지, web data.), 필요 시 LAION-400M 중 일부(115M) 등 최대 1억 장 이상을 활용
- CapFilt를 통해 새로 정제된 데이터셋으로 추가 학습 시, 성능이 상당폭 상승함을 실험적으로 증명하고, 사용하였음. [4.2. Effect of CapFilt]


2. 이미지-텍스트 / 텍스트-이미지 검색(Image-Text / Text-Image Retrieval)
- COCO(5K test), Flickr30K(1K test) 등에서 TR(Text-to-Image Retrieval), IR(Image-to-Text Retrieval)을 측정
- BLIP이 이전 SOTA인 ALBEF, ALIGN 대비 Recall@1 지표에서 +2~3% 이상 차이로 성능이 올라가는 결과를 보인다. [Table 5]
- Zero-shot 설정으로 Flickr30K를 평가했을 때도 CLIP, ALBEF 등에 비해 큰 차이로 우수함을 보임. [Table 6]
- 계산 효율성을 위해, ALBEF(Li et al. (2021a))처럼 ITC loss와 ITM loss를 적절히 이용한 연산을 수행함.
ITC loss는 vector similarity만을 계산하기에,
약 O(N*d)의 time complexity (N=# of data, d=feature dim.)ITM loss는 cross attention 연산이 들어가,
약 O(N^2)의 time complexity (N=# of data, 이 때 TR이라면 # of Image, IR이라면 # of Text.)따라서 ITC loss를 통해 k개의 최상위 후보를 뽑은 뒤, k개 중에서 ITM loss를 통해 rerank 후 선택. (k=128 or 256 - Flickr30k/COCO)

3. 이미지 캡셔닝(Image Captioning)
- COCO(Karpathy split), LM loss로 Finetuning 후, COCO 및 NoCaps 등 OOD(Out-of-domain) dataset에 대해서도 evaluation 수행.
- SimVLM(Wang et al. (2021))에서 했던 것과 같이, 각 caption 맨 앞에 “a picture of”라는 prompt를 붙이는 것이 약간 더 나은 결과를 보였음.
- 이전에 VinVL, LEMON, SimVLM 등에 비견되는 결과를 얻으며, 특정 설정에서는 SOTA 달성
- 14M 크기의 data로 pretrain한 모델에서는 다른 모델들보다 더 나은 결과를 얻었으며, BLIP-129M은 LEMON-200M과 견줄만한 성능을 보임. (LEMON은 BLIP보다 훨씬 계산이 많이 필요하며, 높은 해상도의 이미지를 사용했음에도.)
- 특히, 더 큰 Vision Backbone(ViT-L) + CapFilt를 사용할수록 CIDEr, SPICE 지표 모두 향상됨 [Table 7]
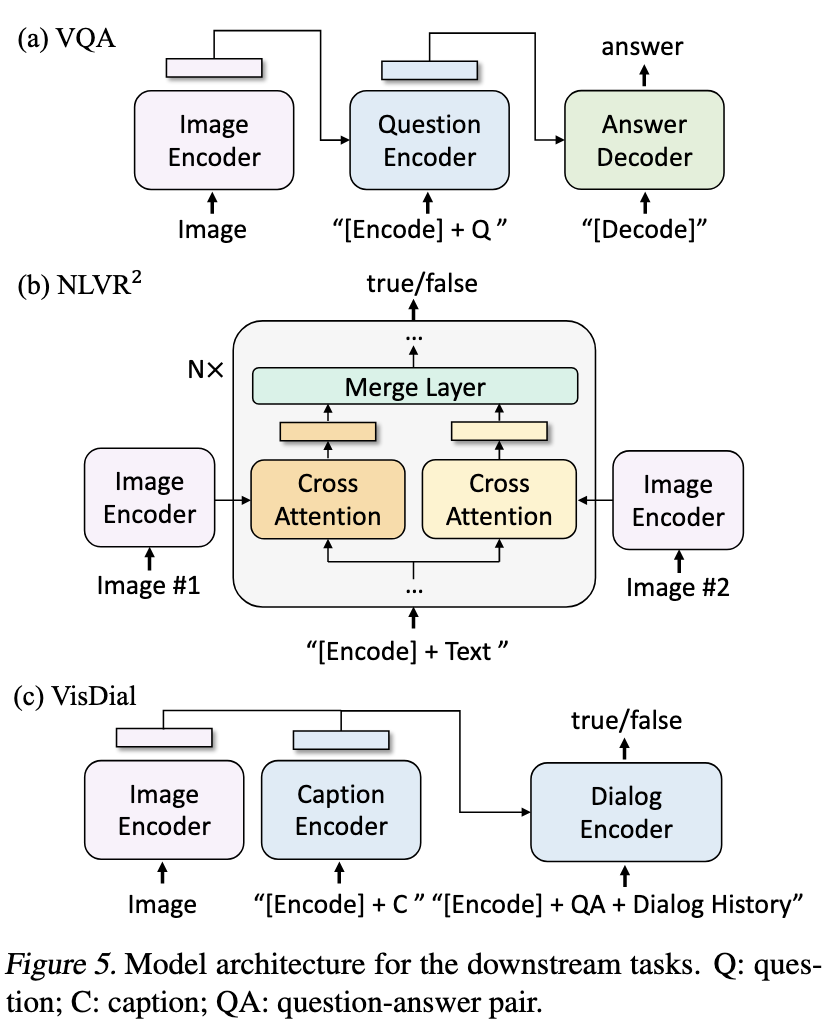

4. VQA(Visual Question Answering)
- VQA v2.0에서, BLIP은 이미지 + 질문을 encoding한 뒤 decoder를 통해 답변을 생성하는 접근을 택한다(multi-answer classification task로써 수행하지 않고, answer-generation task로써 수행하였음). [Figure 5(a)]
- (UNITER: Chen et al., 2020; OSCAR: Li et al., 2020)이 아닌, (ALBEF: Li et al. 2021a)의 방식을 택함.
- LM loss를 통해, ground-truth Answer를 target으로 pre-train 되었음.
- ALBEF 대비 약 +1.6% 개선하였고, 기존 스케일링이 큰 SimVLM과도 유사하거나 조금 뛰어난 성능을 냈다. [Table 8]
5. NLVR2(Natural Language Visual Reasoning)
- 주어진 이미지 쌍과 문장을 기반으로, 참/거짓을 판별하는 task. [Figure 5(b)]
- 이를 통해 모델의 Reasoning 능력 측정.
- extra pretrain을 수행한 ALBEF를 제외한 다른 방법들보다 우수한 성능을 보임. [Table 8]
- 이 task에서는 web image를 통한 additional train이 큰 의미가 없었음.
6. VisDial(Visual Dialog)
- VQA의 확장 버전으로, 이미지-캡션 쌍과 질의응답 이력을 모두 활용하여, 다음 대화 응답을 ranking하는 task.
- BLIP는 여기서도 약간의 finetuning으로 기존 SOTA인 VD-BERT, VD-ViLBERT 등을 넘어서거나 비슷한 수준을 기록한다.
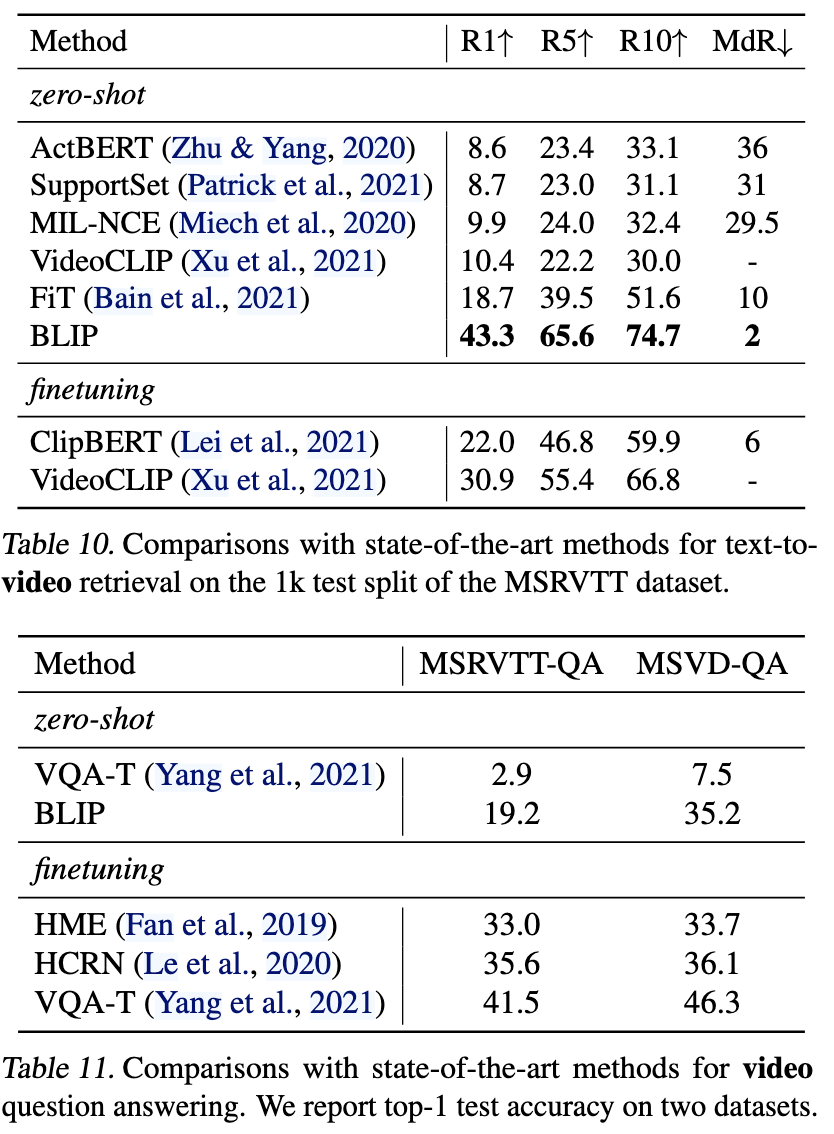
7. Zero-shot for Video-Language task
- MSRVTT(1k test) 등의 dataset에서의 Video-text Retrieval, Video-QA task에서 finetuning 없이 Zero-shot으로 BLIP를 적용했음에도, 기존에 비디오-텍스트 전용으로 학습한 모델보다 훨씬 우수한 성능을 보여준다.
- 이는 이미지 기반 학습만으로도 충분히 일반화된 표현을 학습했음을 시사한다(물론 연속되는 frame 사이의 움직임(temporal information)에 관한 정보는 다루지 않았지만, 고정 프레임들만으로도 좋은 결과를 보였다).
Conclusion
본 논문에서는 BLIP이라는 통합 VLP 프레임워크를 제안하여, 여러 task에서 SOTA를 달성하여 understanding-base, generation-based task 두 측면에서 모두 높은 성능을 낼 수 있음을 입증하였다.
- Multimodal Mixture of Encoder-Decoder(MED):
- unimodal encoder | image-grounded text encoder | image-grounded text decoder라는 세 가지 기능을 하나의 모델이 수행할 수 있도록 만들었다.
- 이미지-텍스트 검색, 캡션 생성, VQA 등을 하나의 model framework를 통해 모두 잘 처리할 수 있게 되었다.
- CapFilt를 통한 데이터 부트스트래핑:
- text를 생성(Captioner)하고, noise text를 제거(Filter)하여, 원본 web text보다 풍부하고 이미지와 매칭이 잘 된 양질의 데이터셋을 만든다.
- 추가적인 라운드나 다양한 캡션 생성 등으로 확장 가능성이 있다.
- 대규모 웹 데이터가 “noise는 심하지만, 단순히 scale-up 함으로써 극복한다”는 기존의 방향성에서 벗어나, noise를 적극적으로 filtering하고 새로운 텍스트를 보강하는 것이 모델 성능을 더욱 향상시킴을 보였다.
- 다양한 downstream vision-language task에서, 기존 SOTA 대비 성능 우위를 보이거나 대등한 성능을 달성했다. 특히, understanding-based, generation-based task 모두에서 우수한 결과를 보인 것에 집중한다.
Personal Comment (리뷰 후기)
- 기존 VLP 연구는 보통 “Encoder-기반 모델은 주로 분류·검색 등의 understanding-based task에만 최적화, Encoder-Decoder 모델은 generation-based task에 좀 더 강점”이라는 식으로 나뉘어 있었다. BLIP는 이를 합친 “혼합형 아키텍처”로, 하나의 프레임워크에서 모두 처리할 수 있었고, 최근의 LVLM 모델들에서도 물론 하나의 프레임워크에서 여러 task를 수행할 수 있게 되었다.
- 선행하여 읽어보았던 CLIP을 보았을 때만 해도, 다량의 웹 이미지를 하나하나 걸러낼 수 없으니 결국 노이즈는 포기하고 다량의 데이터를 때려박는 식으로 해결하는구나 싶었는데, 인간이 검수한 데이터를 활용하여 pre-train한 모델을 이용하여 captioning이나 filtering을 새로 수행하는 것이 신기했다.
- 최근의 VLM에서는 CapFilt에서 발전해서 Self-Supervised Learning을 통한 데이터 정제나, CLIP과 같이 이미 학습된 VLM, 나아가 VLM 자기 자신을 Captioner/Filter로 사용하여 데이터 필터 및 증강을 수행하는 중인 것 같다. 자세한 것은 최근 논문 더 읽고 확인해보는 것으로.. 논문마다 다른 방법 사용하는 것 같기도..
- BLIP도 2022년 논문인데, 거의 3년만에 지금 얼마나 발전한 건지.. 특히 최근 들어 중국 쪽에서 논문이랑 오픈모델 쏟아져나오는 거 보면 무섭다.
- VinVL, LEMON, OSCAR, UNITER와 같은 이전 VLM들에서 사용하였던 Pretrained Object Detector는 여기서부터 잘 사용하지 않고, 거의 다 ViT 기반이 주류로 자리잡힌 것 같다. 아무래도 CNN base이다 보니 Computational Efficiency 같은 문제가 있었겠지 싶다.
정말 자세히 썼는데, 다음 논문리뷰는 좀 힘을 빼고 써야 할 것 같다..^ㅁ^